7.5 – Odds ratio
Introduction
We introduced the concept of odds 7.1 — Epidemiology definitions. As a reminder, odds are a way to communicate the chance (likelihood) that a particular event will take place. Odds are calculates as the number of individuals with the event divided by the number of individuals without the event.
Odds ratio definition: is a measure of effect size for the association between two binary (yes/no) variables. It is the ratio of the odds of an event occurring in one group to the odds of the same event happening in another group. The odds ratio (OR) is a way to quantify the strength of association between one condition and another.
Note 1: Effect size — the size of the difference between groups — is discussed further in Chapter 9.2 and Chapter 11.4.
How are odds ratios calculated? The probabilities are conditional; recall that conditional probability of some event A, given the occurrence of some other event B.
Let  equal probability of the event occurring (y = Yes) in A,
equal probability of the event occurring (y = Yes) in A,  equal probability of the event not occurring (n = No) in A,
equal probability of the event not occurring (n = No) in A,  equal probability of the event occurring in B, and
equal probability of the event occurring in B, and  equal probability of the event not occurring in B.
equal probability of the event not occurring in B.
| A | |||
| Yes | No | ||
| B | Yes | |
|
| No | |
|
|
These sum to one: 
The conditional probabilities are
| A | |||
| Yes | No | ||
| B | Yes |  |
 |
| No |  |
 |
|
and finally then, the odds ratio (OR) is

If you have the raw numbers you can calculate the odds ratio directly, too.
| A | |||
| Yes | No | ||
| B | Yes | a | b |
| No | c | d | |
and the odds ratio is then

or, equivalently

Example
Comparing proportions is a frequent need in court. Gray (2002) provided an example from Title IX of the Education Act of 1972 case Cohen v. Brown University. Under the Act, discrimination based on gender is prohibited. The case concerned participation in collegiate athletics by women. The case data were that of the 5722 undergraduate students, 51% were women, but of the 987 athletes, only 38% were women. A mosaic plot shows graphically these proportions (Fig. 1, males in red bars, females in yellow bars).
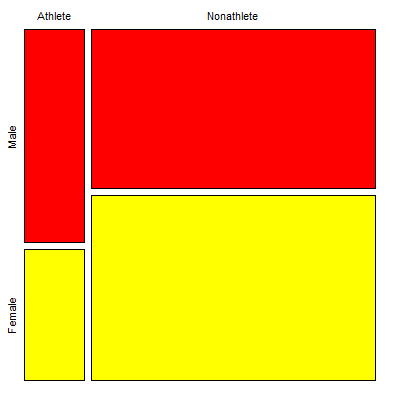
Figure 1. Mosaic plot of athletes to non-athletes in college. Males red, females yellow, data from Gray 2002.
Alternatively, use a Venn diagram to describe the distribution (Fig. 2). Circles that overlap show regions of commonality.
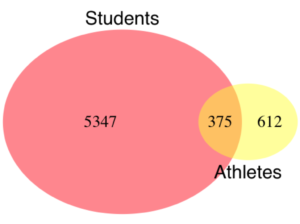
Figure 2. Venn Diagram of athletes to non-athletes in college. Female athletes (n = 375), male athletes (n = 612), data from Gray 2002.
where the orange region

R code for the Venn diagram was
library(VennDiagram)
area1 = 5722
area2 = 987
cross.area = 375
draw.pairwise.venn(area1,area2,cross.area,category=c("Students","Athletes"),
euler.d = TRUE, scaled = TRUE, inverted = FALSE, print.mode = "percent",
fill=c("Red","Yellow"),cex = 1.5, lty="blank", cat.fontfamily = rep("sans", 2),
cat.cex = 1.7, cat.pos = c(0, 180), ext.pos=0)
The question raised before the court was whether these proportions meet the demand of “substantially proportionate.” What exactly the law means by “substantially proportionate” was left to the courts and the lawyers to work out (Gray 2002). Title IX suggests that “substantially proportionate” is a statistical problem and the two sides of the argument must address the question from that perspective.
What is the chance that an undergraduate student was an athlete and female? 38% And the chance that an undergraduate student was an athlete and male? 62% Clearly 38% is not 62%; did the plaintiffs have a case?
Graphs like Figure 1 and Figure 2 help communicate but can’t provide a sense of whether the differences are important. Let’s start by looking at the numbers. Working with the proportions we have the following break down for numbers of students (Table 1) or as proportions (Table 2).
Table 1. Gray’s raw data displayed in a 2 x 2 format.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 612 | 2192 |
| Female | 375 | 2543 | |
Together, the numbers total 5,722.
The Odds Ratio (OR) would be

Or from the proportions (Table 2)
Table 2. Data from Table 1 as proportions.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 0.107 | 0.383 |
| Female | 0.066 | 0.444 | |
adding all of these frequencies together equal 1. Carry out the calculation of odds (Table 3), the conditional probabilities (in bold).
Table 3. Odds calculated from Table 2 inputs.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 0.218
|
0.782
|
| Female | 0.129
|
0.871
|
|




Calculate the odds ratio

Thankfully, whether we use the raw number format or the proportion format, we got the same results!
Odds ratio interpretation
Because the Odds Ratio (OR) was greater than 1, males students were more likely to be athletes than female students. If there was no difference in proportion of male and female athletes, the odds ratio would be close to one. That is a test of statistical inference (e.g., a contingency table), but for now, if one is included in the confidence interval, then this would be evidence that there was no difference between the proportions.
And in R? Simple enough, just create a matrix then apply the Fisher test. which we will discuss further in Chapter 9.5.
title9 <- matrix(c(612, 2192, 375, 2543), nrow=2)) fisher.test(title9)
and results
p-value < 2.2e-16 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 1.641245 2.185576 sample estimates: odds ratio 1.893143
Thankfully, they agree. But note, we now have confidence intervals and a p-value, which we use to conduct inference: were the odds “significantly different from 1?” We would conclude, yes! Between the lower limit (1.64) and the upper limit (2.19), the value “1” was excluded. Moreover, the p-value at 2.2e-16 was much less than the standard type I error cut-off of 5% (see Chapter 8).
Before we leave the interpretation, sometimes a calculated odds-ratio is less than one. If our calculated odds ratio for the Title IX case described in Table 1 was less than 1, (say, the numbers were flipped, Table 4) we then the interpretation would be females were more likely to be athletes on college campus.
Table 4. Table 1 data, but order of entry changed.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Female | 375 | 2543 |
| Male | 612 | 2192 | |
Now, calculating the odds via Fisher exact test, the odds ratio is less than one (0.53):
Fisher's Exact Test for Count Data p-value < 2.2e-16 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 0.4575452 0.6092936 sample estimates: odds ratio 0.5282222
Note this result is for the same data (Table 1 vs Table 4), just the order by which the groups are specified changed. Of course they are related to each other mathematically, and in a simple way. Note that taking the inverse (reciprocal) odds ratio.

will return the comparison we wanted in the first place — the odds a student athlete was male. As long as you keep track of the comparison, of the groups, it may be easier to communicate results when the reported odds ratio is greater than one.
Relative risk v. odds ratio
We introduced another way to quantify this association as the Relative Risk (RR) and Absolute Risk Reductions in the previous section. Both can be used to describe the risk of the treatment (exposed) group relative to the control (nonexposed) group. RR is the ratio the treated to control group. OR is the ratio between odds of treated (exposed) and control (nonexposed). What’s the difference? OR is more general — it can be used in situations in which the researcher choses the number of affected individuals in the groups and, therefore, the base rate or prevalence of the condition in the population is not known or is not representative of the population, whereas RR is appropriate when prevalence is known (this is a general point, but see Schechtman 2002 for a nice discussion).
The odds ratio is related to relative risk, but not over the entire range of possible risk. Odds of an event is simply the number of individuals with the event divided by the number without the event. Odds of an event therefore can range from zero (event cannot occur) to infinity (event must occur). For example, odds of eight (1.89:1) means that nearly two male students were student athletes at Brown University for every one female student.
In contrast, the risk of an event occurring is the number of individuals with the event divided by the total number of people at risk of having that event. Risk is expressed as a percentage (Davies et al 1998). Thus, for our example, odds of 1.89:1 correspond to a risk of 1.89 divided by (1 + 1.89) equals 65%.
To get the relative risk we can use

or 1.7% for our example.
In this example we could use either odds or relative risk; the key distinction is that we knew how many events happened in both groups. If this information is missing for one group (e.g., control group of the case-control design), then only the odds ratio would be appropriate.
From cumulative wisdom in the literature (e.g., Tamhane et al 2107), if prevalence is less than ten percent, OR ≈ RR. We can relate RR and OR as

where n11 and n21 are the frequency with the condition for group 1 and group 2, respectively, and n12 and n22 are the frequency without the condition for group 1 and group 2, respectively. For the examples on this page group 1 is the treatment group and group 2 is the control group.
Hazard ratio
The hazard ratio is the ratio of hazard rates. Hazard rates are like the relative risk rates, but are specific to a period of time. Hazard rates come from a technique called Survival Analysis (introduced in Chapter 20.9). Survival analysis can be thought of as following a group of subjects over time until something (the event) happens. By following two groups, perhaps one group exposed to a suspected carcinogen vs. another group matched in other respects except the exposure, at the end of the trial, we’ll have two hazard rates: the rate for the exposed group and the rate for the control group. If there is no difference, then the hazard ratio will be one.
Hazard ratios are more appropriate for clinical trials; relative risk is more appropriate for observational studies.
For a hazard ratio, it is often easier to think of it as a probability (between 0 to 1). To translate a hazard ratio to a probability use the following equation

Questions
- Distinguish between odds ratio, relative risk, and hazard ratio.
- Refer to problem 1 introduced in 7.4 – Epidemiology: Relative risk and absolute risk, explained
- In 2017-18, males were 43% of the 18.8 million enrolled students at U.S. 2- and 4-year colleges, and 56% of the 4.95 million student athletes at that time. Calculate the odds, and confidence interval, that a student athlete was male in 2017-18. How do your results compare to the OR of 1.89 for Table 1 (from Gray 2002)?
Chapter 7 contents
4.4 – Mosaic plots
Introduction
Mosaic plots are used to display associations among categorical variables. e.g., from a contingency table analysis. Like pie charts, mosaic plots and tree plots (next chapter) are used to show part-to-whole associations. Mosaic plots are simple versions of heat maps (next chapter). Used appropriately, mosaic plots may be useful to show relationships. However, like pie-charts and bar charts, care needs to be taken to avoid their over use; works for a few categories, but quickly loses clarity as numbers of categories increase.
In addition to the function mosaicplot() in the base R package, there are a number of packages in R that will allow you to make these kinds of plots; depending on the analyses we are doing we may use any one of three Rcmdr plugins: RcmdrPlugin.mosaic (depreciated), RcmdrPlugin.KMggplot2, or RcmdrPlugin.EBM.
Example data
Table 1. Records of American and National Leagues baseball teams at home and away midway during 2016 season
| No | Yes | |
|---|---|---|
| AL | 10 | 5 |
| NL | 7 | 8 |
The configuration of major league baseball (MLB) parks differ from city to city. For example, Boston’s American League (AL) Fenway Park has the 30-feet tall “Green Monster” fence in left field and a short distance of only 302 feet along the foul line to right field fence. For comparison, Globe Life Park in Arlington, TX the distance along the foul lines left field (332 feet) and right field (325 feet). So, it suggests that teams may benefit from playing 81 games at their home stadium. To test this hypothesis I selected Win-Loss records of the 30 teams at the midway point of the 2016 season. Data are shown in the Table 1.
mosaicplot() in R base
The function mosaicplot() is included in the base install of R. The following code is one way to directly enter contingency table data like that from Table 1.
myMatrix <- matrix(c(10, 5, 7, 8), nrow = 2, ncol = 2, byrow = TRUE)
dimnames(myMatrix) <- list(c("AL", "NL"), c("No","Yes"))
myTable <- as.table(myMatrix); myTable
mosaicplot(myTable, color=2:3)
The simple plot is shown in Figure 1. color = “2” is red, color = “3” is green.
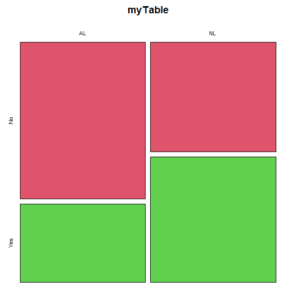
Figure 1. Mosaic plot made with basic function mosaicplot().
mosaic plot from EBM plugin
A good option in Rcmdr is to use the “evidence-based-medicine” or “EBM” plug-in for Rcmdr (RcmdrPlugin.EBM). This plugin generates a real nice mosaic plot for 2 X 2 tables.
After loading the EBM plugin, restart Rcmdr, then select EBM from the menu bar and choose to “Enter two-way table…”
Figure 2. First steps to make mosaic plot in R Commander EBM plug-in.
Complete the data entry for the table as shown in the image below. After entering the values, click the OK button.
Figure 3. Next steps to make mosaic plot in R Commander EBM plug-in.
Along with the requested statistics a mosaic plot will appear in a pop-up window.

Figure 4. Mosaic plot made from R Commander EBMplug-in
mosaic-like plot KMggplot2 plugin
The KMggplot2 plugin for Rcmdr will also generate a mosaic-like plot. After loading the KMggplot2 plugin, restart Rcmdr, then load a data set with the table (e.g., MLB data in Table 1). Next, from within the KMggplot2 menu select, “Bar chart for discrete variables…”
Figure 5. First steps to make mosaic plot in R Commander KMggplot2 plug-in.
From the bar chart context menu make your selections. Note that this function has many options for formatting, so play around with these to make the graph the way you prefer.
Figure 6. Next steps to make mosaic plot in R Commander KMggplot2 plug-in.
And here is the resulting mosaic-like plot from KMggplot2.
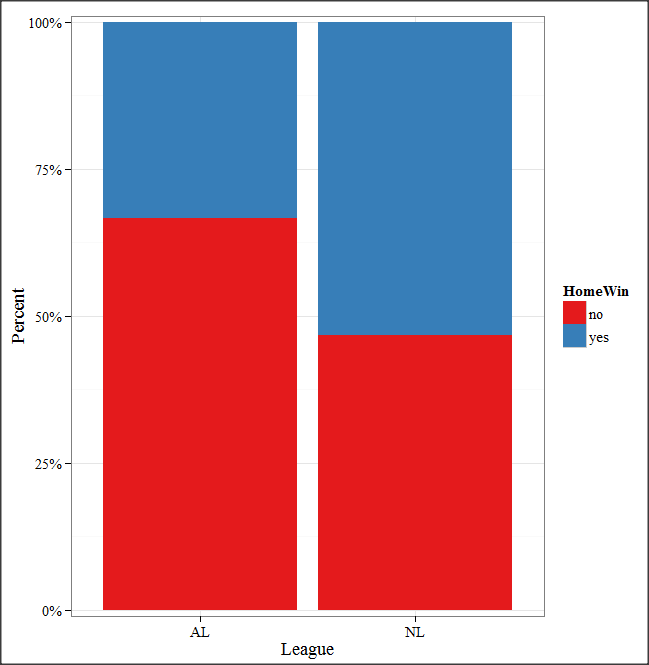
Figure 7. Mosaic-like plot made from R Commander KMggplot2 plug-in.
Questions
1. Most US states have laws that dictate pre-employment drug testing for job candidates; Interestingly, states are increasingly legalizing marijuana use. Data for states plus District of Columbia are presented in the table. Make a mosaic plot of the table.
Table 2. Marijuana use is US states, legal or not legal
| Marijuana-use legal | Marijuana-use not legal | |
|---|---|---|
| Yes | 19 | 12 |
| No | 14 | 6 |
Data adopted from https://www.paycor.com/resource-center/pre-employment-drug-testing-laws-by-state
Depreciated material
As of summer 2020, Rcmdrplugin.mosaic is depreciated. While you can install the archived version, it is not recommended. Therefore, this material is left as is but for information purposes only. For a simple mosaic plot in Rcmdr I recommend working with the RcmdrPlugin.EBM.
Download the RcmdrPlugin.mosaic package, start Rcmdr, then navigate to Tools and choose Load Rcmdr plug-in(s).… Select Rcmdrplugin.mosaic (Fig. 8), then restart Rcmdr (Fig. 9). The plugin adds mosaic plot to the regular Graphics menu of Rcmdr.
Figure 8. Screenshot of popup menu from Rcmdr with mosaic plugin selected.
Figure 9. After clicking OK (Fig 8), click Yes to restart Rcmdr. The plugin will then be available.
Load a data set with 2X2 arranged data, or create the variables yourself (Yikes, 30 rows!). The mosaic plugin requires that you submit data in a table format. We can check whether our data are currently in that format. At the R prompt type
is.table(MLB)
And R will return
[1] FALSE
(To be complete, confirm that the data set is a data.frame: is.data.frame(MLB).)
You will need a table before proceeding with the mosaic plug-in. then create a table using a command like the one shown below.
MLBTable <- xtabs(~League+HomeWin, data=MLB)
Once the table is ready, select “mosaic or assoc plot” from the Rcmdr Graphics menu (Fig. 10)
Figure 10. How to access the mosaic plot in R Commander.
A small window will pop up that will allow you to select the table of data you just created (Fig. 11). Note that you may need to hunt around your desktop to find this menu! Select the table (in this example, “MLBTable), then click on “Create plot” button.
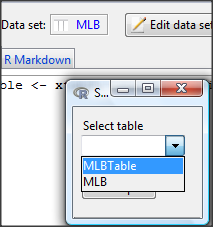
Figure 11. Screenshot of popup menu in mosaic plugin in R Commander.
R Note: The popup from the mosaic menu shown in Fig. 11 will also display the data.frame MLB. If you mistakenly select the dataframe MLB, you’ll get an error message in Rcmdr (Fig. 12). The plugin behaves erratically if you select MLB: On my computer, the function hangs and requires restarting R.
Figure 12. Error message as result of selecting a dataframe for use in mosaic plugin.
After you select the table, two additional windows will pop up: on the left (Fig. 13) is the context menu to change characteristics of the mosaic plot; on the right (not shown) will be a mosaic plot itself in default grey scale colors.
Figure 13. Options for the mosaic plot
At a minimum, change the plot from grey scale to a colorized version by checking the box next to the “Colorize last variable” option. The new plot is shown in Figure 14.
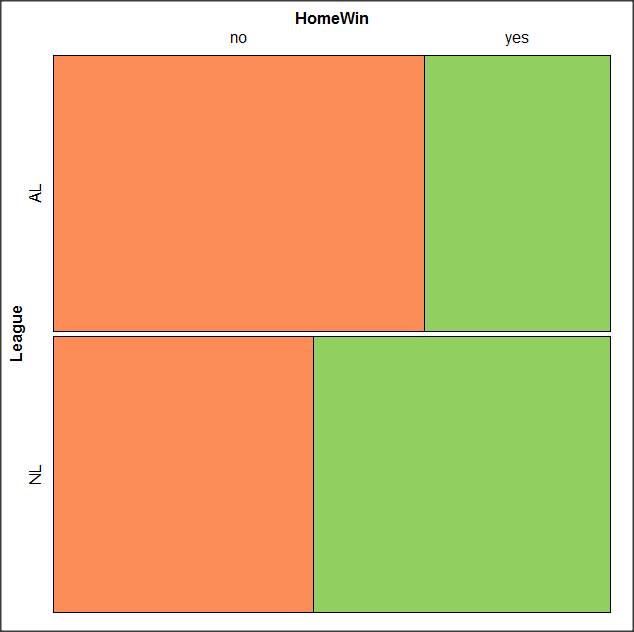
Figure 14. Our new mosaic plot.
OK. Take a moment and look at the plot. What conclusions can be made about our hypothesis — are there any differences between the leagues for home versus road Wins-Loss records?
By default the mosaic command copies the command to the R window. You can change the graph by taking advantage of the options in the brewer palette. Here’s the command for the mosaic image above.
mosaic(structable(MLBTable), highlighting=2, highlighting_fill=brewer.pal.ext(2,"RdYlGn"))
Change the options in the brackets following “brewer.pal.ext.” For example, replace RdYlGn with Blues to make a plot that looks like the following
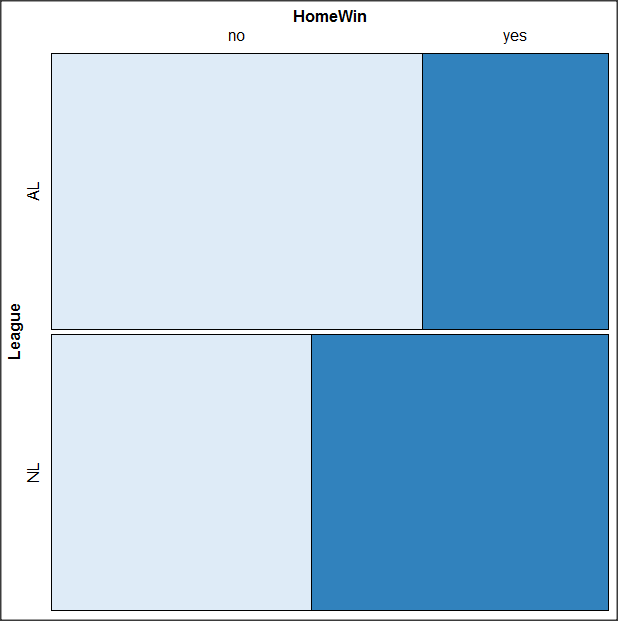
Figure 15. Mosaic plot with changed color scheme.
The colors are selected from the Rcolorbrewer package. For more, see this blog for starters.
Chapter 4 contents
- Graphs and tables (How to report statistics)
- Bar (column) charts
- Histograms
- Box plot
- Mosaic plots
- Scatter plots
- Add a second Y axis
- Q-Q plot
- Ternary plots
- Heat maps
- Graph software
- References and suggested readings