7.2 – Epidemiology basics
Introduction
A principle aim of epidemiology is to identify frequency and causes of illnesses. Kinds of evidence gathered range from case studies to randomized controlled trials, to meta-analysis and systematic reviews. In turn, how these kinds of evidence are evaluated and turned into policy recommendations generally accounts for additional concerns eg, GRADE – Grading of Recommendations Development, Assessment and Evaluation Schünemann et al 2023). Learning about conditional probability in biostatistics is essential for discussing evidence because it provides a rigorous framework for updating strength of evidence based on new, specific information. It allows for the objective assessment of how new evidence — results from a clinical test — influences the likelihood of a hypothesis — presence/absence of disease for a patient. Conditional probability analysis allows interpretation of a positive test result in the context of disease prevalence, which may lead to the paradoxical conclusion that a test with high sensitivity applied to a person belonging to a low at risk group is more likely a false positive than evidence of a true positive.
Thus, to introduce conditional probability, I have elected to push you into epidemiology and risk analysis. We introduced epidemiology definitions and here, we build on basic terminology of epidemiology. Epidemiology is the study of the causes and distribution of health-related events in a population. It is has been called the basic science of public health (p. 16, Decker 2008).
Prevalence rate
Prevalence of a disease (condition), is defined as the proportion of the population that has the disease (condition) at a point or duration in time. The prevalence statistic is the ratio of the number of existing cases divided by the total population.
For example, prevalence of Type 2 diabetes in Hawai`i. The 2020 populations was about 1.4 million. A survey was conducted on a random of 1000 individuals and 80 were reported to have Type 2 diabetes. What is the estimated prevalence of Type 2 diabetes in Hawai`i?
Start from perspective — what if we actually have something close to a census count? For the actual estimates, see the report at the Hawaii State DOH website. With every estimate of a statistic, we need a confidence interval (CI). An approximate (good for large samples) formula for the 95% CI of prevalence is

where  is the 2010 prevalence in the population (8.3%), N is the population size (1,360,301), and z is the standard normal probability. For a 95% CI, then we want z95%.
is the 2010 prevalence in the population (8.3%), N is the population size (1,360,301), and z is the standard normal probability. For a 95% CI, then we want z95%.
If you recall, we can get this from our standard normal probability table, or directly from R. We want to know z that is in the ± 2.5% tails of the distribution (that’s 0.05 ÷ 2, see Ch 8.4 – Tails of a test). Our R code then is
qnorm(c(0.025), mean=0, sd=1, lower.tail=FALSE)
which returns
[1] 1.959964
You should confirm that setting lower-tail = TRUE yields -1.96 (rounded).
Alternately, if using Rcmdr: Distributions → Continuous distributions → Normal distribution → Normal quantiles… (Fig 1).
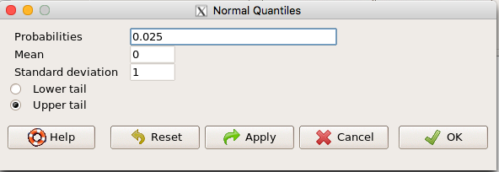
Figure 1. R Commander popup menu for Normal quantiles.
Thus, for our example, the 95% CI was ( ; our confidence in our estimate of the prevalence of diabetes in Hawaii is between 8.25% and 8.35%. Again, note that for our purposes it is OK to calculate the approximate confidence interval, replace
; our confidence in our estimate of the prevalence of diabetes in Hawaii is between 8.25% and 8.35%. Again, note that for our purposes it is OK to calculate the approximate confidence interval, replace  with
with  (for large N, the differences are observed in the 0.001 decimal).
(for large N, the differences are observed in the 0.001 decimal).
Prevalence: R code
Rather than census counts, more likely we have results of smaller surveys. We use the epi.conf() function from the epiR package. Code adapted from example provided in epiR_descriptive vignette.
Note 1: Many R packages include vignettes, which, together with the package manual, is often helpful to understand what a function is intended to do and how to get the most from the function. R code to call all vignettes available for a package, e.g., epiR:
vignette(package="epiR")
which will return names of available vignettes. For epiR, these are
epiR_descriptive Descriptive epidemiology (source, html) epiR_surveillance Disease surveillance (source, html) epiR_measures_of_association Measures of association (source, html) epiR_sample_size Sample size calculations (source, html)
To call up the vignette we need for this example,
vignette("epiR_descriptive", package="epiR")
which brings up the page (assuming you installed the html help files during installation of base R).
library(epiR) pop.Hawaii = 1.4e06 pop.Survey = 1000 type2.Survey = 80 Table.2 <- as.matrix(cbind(type2.Survey, pop.Survey)) epi.conf(Table.2, ctype = "prevalence", method = "exact", N = pop.Hawaii, design = 1, conf.level = 0.95) * 100
R output
est lower upper 1 8 6.394198 9.857978
Thus, estimated Type 2 diabetes prevalence from the survey was 8, with 95% confidence interval 6.4 to 9.9 cases per 100 individuals. From 2020 U.S. Census, Hawai`i population was 1,455,271.
Note 2: Type 2 diabetes is one of many conditions for which prevalence is greater among Native Hawaiian and Pacific Islander populations compared to other groups in Hawai’i (Galinski et al 2016); these are called health disparitiess.
Incidence rate
Incidence of a disease (or condition) is defined as the occurrence of new cases of a disease. The simplest way to view incidence is that if everyone was followed for the same period of time, then incidence rate is the number of new cases since the start of the study divided by the total population. This is too simplistic, so we define a better metric called person-time. Incidence rate (IR) is then the ratio of the number of new cases divided by total person-time.
Again, incidence rate is an estimate. Therefore, we need a confidence interval. Assuming the population is large, then confidence interval can be calculated as

where IR is the incidence rate, T is the person-time, N is the number of events or cases, and z again is the standard normal probability (z ± 1.96 for 95% confidence interval).
For our example, N = 3 cases, T = 236 p-d, so 95% CI is (11.3%, 14.1%).
Person-time
Person-time can be days, months, years. Person-time is best defined with an example.
Five men join a study that will last 70 days. These men were selected because they had suffered a myocardial infarction (MI) and at the start of the study, they receive the same treatment. The outcome of the study is whether or not the subjects suffer a second MI.
The results are shown below
Subject A, 53 days
Subject B, 70 days
Subject C, 24 days
Subject D, 70 days
Subject E, 19 days
Add up the person days,

Now calculate the incidence rate,

that’s 3 cases (A, C, E) divided by 236 p-d = 0.0127. Multiply this by 1000 and we get our final answer for the incidence rate, 12.7 per person-days.
Incidence rate: R code
Incidence rate of myocardial infarction (MI) study. Code adapted from example provided in epiR_descriptive vignette.
ncas = 3 ntar = 236 tmp <- as.matrix(cbind(ncas, ntar)) epi.conf(tmp, ctype = "inc.rate", method = "exact", N = 1000, design = 1, conf.level = 0.95) * 1000
R output
est lower upper ncas 12.71186 2.621492 37.14946
The incidence rate of myocardial infarction was 12.7 (95% CI 2.6 to 37.2) cases per 1000 person-days.
Age-specific rates
Incidence or prevalence rates may be reported for specific age groups. For example, we can distinguish between number of live births in Hawaii in 2017, and numbers of live births by age group of the mother.
Age-adjusted rates
If populations with different age demographics, then the convention is to adjust the populations to a standard reference population with known age and other demographic properties. For example, the CDC uses the 2000 census as the standard population (CDC definitions, age adjustment, retrieved January 2023).
Questions
- Calculate the confidence interval of type 2 prevalence in Hawai`i with the 2020 census population value. How much did it change?
- Recalculate the confidence interval for a 99% confidence interval. Which estimate communicates greater confidence in the estimate?
Quiz
Quiz Chapter 7.2
Epidemiology basics
Chapter 7 contents
7.1 – Epidemiology definitions
Introduction
This subchapter may lack for drama, but let’s start by providing a list of key terms with definitions as you start our introduction to epidemiology. More definitions will follow in the sections as well.
Definitions
Absolute risk: The probability that a specified event will occur in a specified population. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
Absolute risk reduction (ARR): the decrease in risk of an event in an exposed (treatment) group compared to an unexposed (control) group. Also called the risk difference.  , see Contingency table. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
, see Contingency table. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
Contingency table, also called cross tabulation or crosstab, is a display of counts of variables in a matrix format. We briefly introduced the contingency table in Chapter 5.1. In epidemiology, rows of contingency table represent treatment or exposure groups, columns represent outcomes.
Table 1. A 2 X 2 contingency table
| Outcome | ||
| Yes | No | |
| Treatment or exposed group | a | b |
| Control or nonexposed group | c | d |
The 2X2 contingency table is referred to frequently in this chapter and again in Chapter 9.
R code
a = 4; b = 46; c = 5; d = 45
Table1 <- matrix(c(a,b,c,d), 2, 2, byrow=TRUE, dimnames = list(c("Treatment", "Control"), c("Yes", "No"))); Table1
R output
Yes No Treatment 4 46 Control 5 45
In statistical classification, a field dedicated to establishing algorithms for correctly identifying and predicting classes of data, e.g., correct disease diagnosis or , the 2X2 contingency table is often called a confusion or error matrix (Greene 2003). Machine learning methods are often built on developments from statistical classification findings (Michie et al 1995). We expand on contingency tables in Chapter 7.4 and Chapter 9.2.
Control event rate (CER): How often an event occurs in the control group.  , see Contingency table.
, see Contingency table.
Diagnosis: identification of the nature of a disease or condition.
Event: From probability theory, an event is a set of one or more outcomes to which a probability is assigned to each outcome.
Experimental event rate (EER): How often an event occurs in the treatment group.  , see Contingency table.
, see Contingency table.
Exposure risk: the potential for harm from contact with or vulnerability to a hazard or risk factor.
Hazard: anything that can cause harm.
Incidence: the number of newly diagnosed individuals in a population having a condition, disease or other characteristic. Compare to prevalence.
Likelihood: In every-day English, the term likelihood and probability mean the same thing — the chance that an event will occur. In statistics, however, probability refers to possible outcomes in the future — a prediction for an event to occur, whereas likelihood is associated with the possible explanation (hypothesis) for the outcome that has already occurred, the past. Put another way, likelihood quantifies how likely is the data we observe, given the hypothesis (cf. excellent discussion by Gallistel 2015)? We will look at likelihood methods in practice in subsequent chapters.
Negative predictive value of a test (NPV), defined as the probability that a negative test result identifies a person who truly does not have the disease. Calculated as the total number of individuals without the disease divided by the total that tested negative. 
Number needed to treat (NNT): the inverse of the absolute risk reduction.  . See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
Odds, the ratio (OR) of two probabilities: the probability of getting a one on throwing a dice is  , the probability of not getting a one is
, the probability of not getting a one is  , therefore the odds of getting a one are 1 to 5.
, therefore the odds of getting a one are 1 to 5.  . See Ch07.5 – Odds ratio.
. See Ch07.5 – Odds ratio.
Outcome, the single result from a random experiment. For example, result of a single coin toss is “heads.” Results of a birth, the outcome is the child born is a singleton, single birth.
Per capita rate, Latin phrase, for each head, meaning per person.
Positive predictive value of a test (PPV), defined as the probability that a positive test result identifies a person who truly has the disease. Calculated as the total number of individuals with the disease divided by the total that tested positive. 
Posttest probability refers to the probability that the patient has the disease after the results of the test are known.
Pretest probability is the prevalence of the disease, i.e., the chance that the a randomly selected person from the population has the disease.
Prevalence: The proportion of individuals in a population having a condition, disease, or characteristic. Compare to incidence.
Probability, defined in Chapter 6.1.
Prognosis, how a disease plays out.
Relative risk: Ratio of the risk of an event among those exposed to the risk factor to the risk among those not exposed to the risk factor. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
Relative risk reduction (RRR): is a measure calculated by dividing the absolute risk reduction by the control event rate. See Ch07.4 – Epidemiology: Relative risk and absolute risk, explained.
Risk: Probability of an event. Risk is not restricted to just bad events, but refers to the uncertainty of a particular event (e.g., the risk that a child will be born male seems a melodramatic statement, but it is accurate as far as this definition goes).
Therapy, treatment intended to treat, relieve, or cure a disorder of condition.
Questions
- Compare and contrast ARR and RRR.
- What’s the difference between event, hazard, and risk?
- What’s the difference between incidence and prevalence?
- What’s the difference between diagnosis and prognosis?
- What’s the implication of a NNT greater than 100 in terms of the utility of a proposed therapy or treatment?
Quiz
Quiz Chapter 7.1
Epidemiology definitions
Chapter 7 contents
- Introduction
- Epidemiology definitions
- Epidemiology basics
- Conditional Probability and Evidence Based Medicine
- Epidemiology: Relative risk and absolute risk, explained
- Odds ratio
- Confidence intervals
- References and suggested readings
6.11 – F distribution
Introduction
The F distribution is the probability distribution associated with the F statistic and named in honor of R. A. Fisher. The F distribution is used as the null distribution of the ANOVA test statistic. The F distribution is the ratio of two chi-square distributions, with degrees of freedom v1 and v2 for numerator and denominator, respectively.
Note 1: George W. Snedecor named the F-distribution after Sir Ronald Fisher in honor of his work on variance ratio. Fisher first developed the concept of the variance ratio in the 1920s, calling it the “general z-distribution”.
We can for illustration purposes define the F statistic as a ratio of two variances,

Note 2: We test the ratio of variances to infer the difference between means because a large ratio suggests the variation between groups is much greater than the variation within groups. This comparison, key to Analysis of Variance (ANOVA), allows us to decide if the group means are different beyond random chance.
The F statistic has two sets of degrees of freedom, one for the numerator and one for the denominator. The actual formula for the F distribution is quite complicated and in general we don’t use the F distribution in a way that involves parameter estimation. Rather, it is used in evaluating the statistical significance of the F statistic. Therefore, we produce but a few graphs and a table of critical values to illustrate the distribution.
We call the result of this calculation the F test statistic. We evaluate how often that value or greater of a test statistic will occur by applying the F distribution function. A few graphs to get a sense of what the distribution looks like for varying v1, v2 held to ten degrees of freedom (Fig 1).
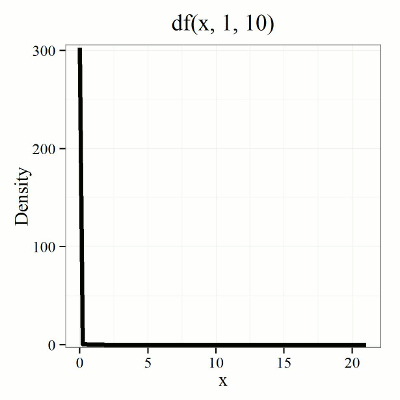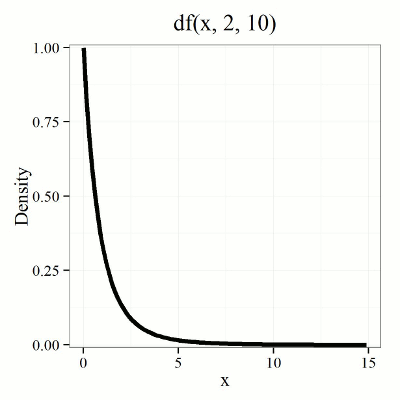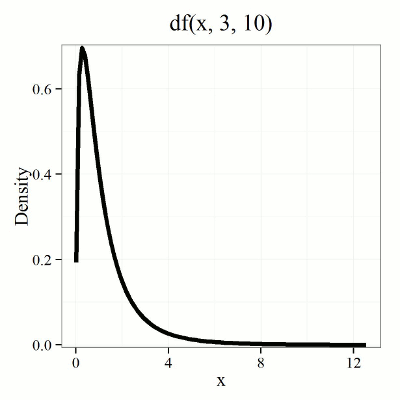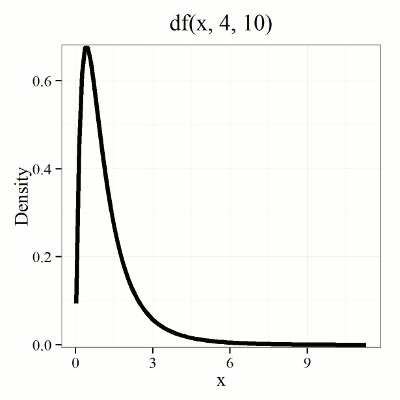
Figure 1. Animated GIF plot of F distribution value for range of degrees of freedom.
By convention in the Null Hypothesis Significance Testing protocol (NHST), we compare the test statistic to a critical value. The critical value is defined as the value of the test statistic that occurs at the Type I error rate, which is typically set to 5%., per our presentations in Chapter 6.7, 6.9, and 6.10. The justification for NHST approach to testing of statistical significance is developed in Chapter 8.
Table of Critical values of the F distribution, one tail (upper)
Degrees of freedom v1 = 1 – 4, v2 = 10
| Fv1, 10 | α = 0.05 | α = 0.025 | α = 0.01 |
| 1 | 4.964 | 6.937 | 10.044 |
| 2 | 4.103 | 5.456 | 7.559 |
| 3 | 3.708 | 4.826 | 6.552 |
| 4 | 3.478 | 4.468 | 5.994 |
For the complete F table see Appendix 20.4
χ2, t and F distributions are related
χ2, t and F distributions are all distributions indexed by their degrees of freedom. With some algebra, these three distributions can be shown to be related to each other. The probabilities tabled in the chi-squared are part of the F-distribution.
Some interesting relationships between the F distribution and other distributions can be shown. By definition we claimed that the F distribution is built on ratio of chi-square distributions, so that should indicate to you the relationship between the two kinds of continuous probability distributions. However, one can also show relationships to other distributions for the F distribution. For example, for the case of v1 = 1 and v2 = any value, then F1,v2 = t2, where t refers to the t distribution.
Questions
- What happens to the shape of the F distribution as df1 is held constant, but df2 degrees of freedom are increased from 1 to 5 to 20 to 100?
- What happens to the shape of the F distribution as df1 degrees of freedom are increased from 1 to 5 to 20 to 100 while df2 is held constant?
Be able to answer these questions using the F table, Appendix 20.4, or using R/Rcmdr
- For probability α = 5%, and numerator degrees of freedom equal to 1, what is the critical value of the F distribution (upper tail) for 5 degree of freedom? For 20 df? For 30 df?
Quiz Chapter 6.11
F distribution
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate (Z)
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings
6.10 – t distribution
Introduction
Student’s t distribution is a sampling distribution where values are sampled from a normal distributed population, but σ the standard deviation and μ the mean of the population are not known. When sample size is large and we know σ the standard deviation, we would use the Z-score to evaluate probabilities of the sample mean. The t-distribution applies when σ is not known and sample size is small (eg, less than 30, per rule of thirty).
Note 1: According to Wikipedia and sources therein, Student was the pseudonym of William Sealy Gosset, who came up with the t-test and t-distribution.
Because of its thicker tails compared to the normal distribution, the t-distribution accounts for the uncertainty in estimating the population variability. This is important because we would require a more extreme value to be considered “statistically significant” compared to the normal distribution, making your conclusions more conservative.
Note 2: “Conservative” is a desirable characteristic in statistical inference because it means a procedure is less likely to result in a Type I error.
The equation of the t-test is

where the difference between “X bar,” the sample mean, and μ, the population mean, is divided by the standard error of the mean,  , defined in Chapter 3.2 and again in Chapter 3.3. This formulation of the t-test is called the one sample t-test (Chapter 8.5). We call the result of this calculation the test statistic for t. We evaluate how often that value or greater of a test statistic will occur by applying the t distribution function.
, defined in Chapter 3.2 and again in Chapter 3.3. This formulation of the t-test is called the one sample t-test (Chapter 8.5). We call the result of this calculation the test statistic for t. We evaluate how often that value or greater of a test statistic will occur by applying the t distribution function.
There are many t-distributions, actually, one for every degree of freedom. Like the normal distribution, the t distribution is always symmetrical about the mean. But it is stacked up (leptokurtic) around the middle at low degrees of freedom. As degrees of freedom increase, the t distribution spreads and becomes increasingly like the normal distribution.
Relationship between t distribution and standard normal curve.
First, here is our standard normal plot, mean = 0, standard deviation = 1 (Fig 1).
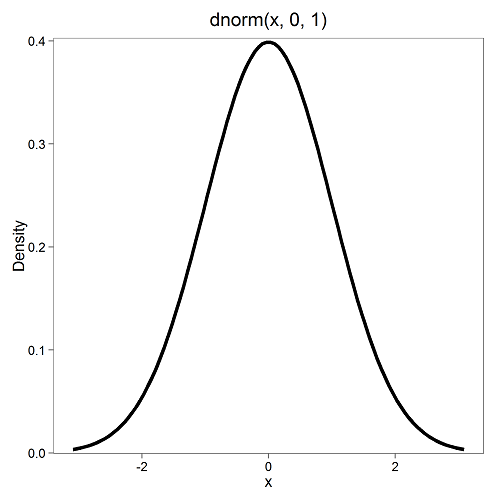
Figure 1. Density plot of standard normal distribution
Next, here’s the t-distribution for five degrees of freedom (Fig 2).
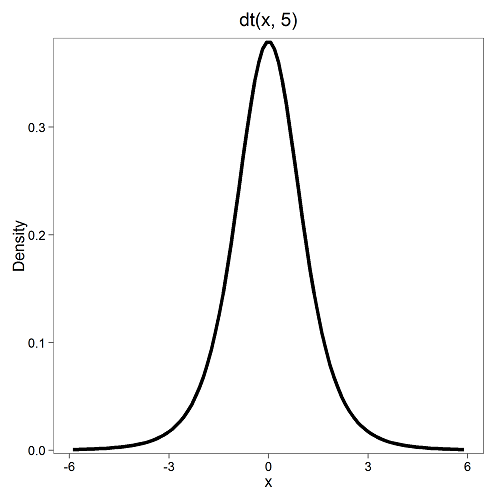
Figure 2. Density plot of t-distribution for five degrees of freedom.
Lets see what happens to the shape of the t-distribution as we increase the degrees of freedom from df = 5, 10, 20, 50, 1000, 10000 (Fig 3). The last graphic in the series is the standard normal curve again (Fig 3).
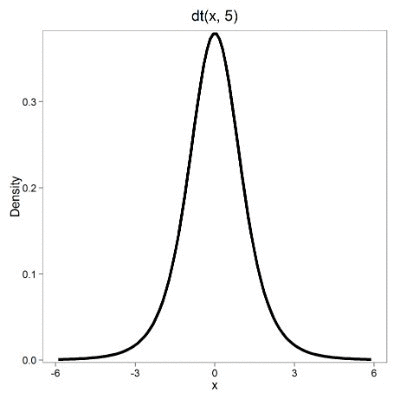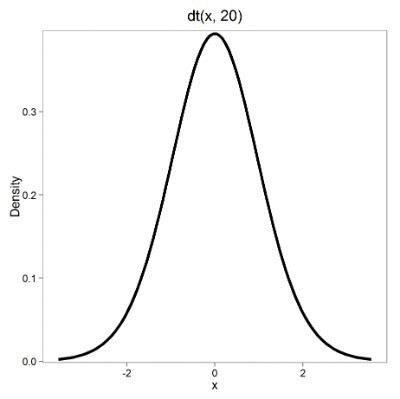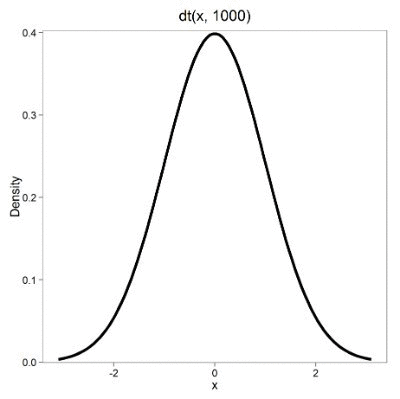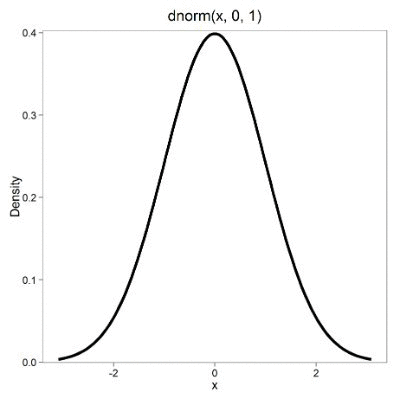
Figure 3. Animated GIF of density plot t distribution, from df = 5 to 10,000 plus standard normal curve.
By convention in the Null Hypothesis Significance Testing protocol (NHST), we compare the test statistic to a critical value. The critical value is defined as the value of the test statistic that occurs at the Type I error rate, which is typically set to 5%. We introduced logic of NHST approach in Chapter 6.9 with the chi-square distribution. Again ,this is just an introduction; we teach it now as a sort of mechanical understanding to develop. The justification for this approach to testing of statistical significance is developed in Chapter 8.
Table of Critical values of the t distribution for df 1 – 5, one tail (upper)
| df | α = 0.05 | α = 0.025 | α = 0.01 |
| 1 | 6.314 | 12.706 | 31.820 |
| 2 | 2.920 | 4.303 | 6.965 |
| 3 | 2.353 | 3.182 | 4.541 |
| 4 | 2.132 | 2.776 | 3.747 |
| 5 | 2.015 | 2.571 | 3.365 |
See Appendix 20.3 for a complete table of t-distribution.
Questions
Be able to answer these questions using the t table, Appendix 20.3, or using Rcmdr
- For probability α = 5%, what is the critical value of the t distribution (upper tail) for 1 degree of freedom? For 5 df? For 20 df? For 30 df?
- The value of the t test statistic is given as 12. With 3 degrees of freedom, what is the approximate probability of this value, or greater from the t distribution?
Quiz Chapter 6.10
t distribution
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate (Z)
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings
6.9 – Chi-square distribution
Introduction
As noted earlier, the normal deviate or Z score can be viewed as randomly sampled from the standard normal distribution. The chi-square distribution describes the probability distribution of the squared standardized normal deviates with degrees of freedom, df, equal to the number of samples taken. (The number of independent pieces of information needed to calculate the estimate, see Ch. 8.) We will use the chi-square distribution to test statistical significance of categorical variables in goodness of fit tests and contingency table problems.
The equation of the chi-square is

where k is the number of groups or categories, from 1 to k, and fi is the observed frequency and fi “hat” is the expected frequency for the kth category. We call the result of this calculation the chi-square test statistic. We evaluate how often that value or greater of a test statistic will occur by applying the chi-square distribution function. Graphs to show chi-square distribution for degrees of freedom equal to 1 – 5, 10, and 20 (Fig 1).
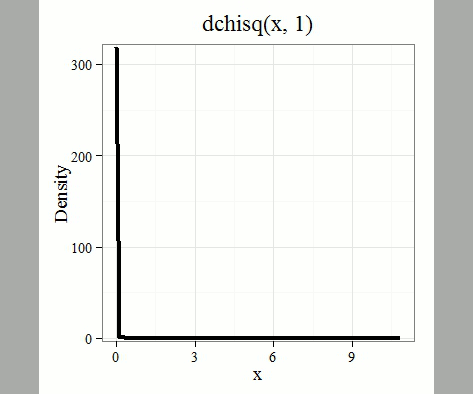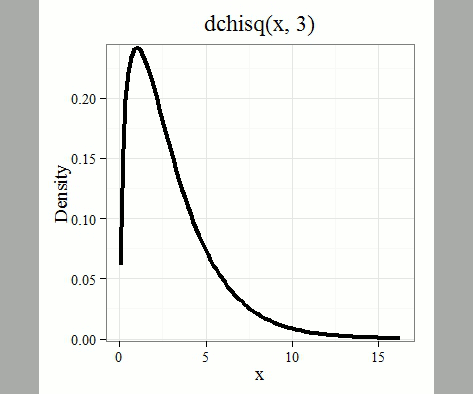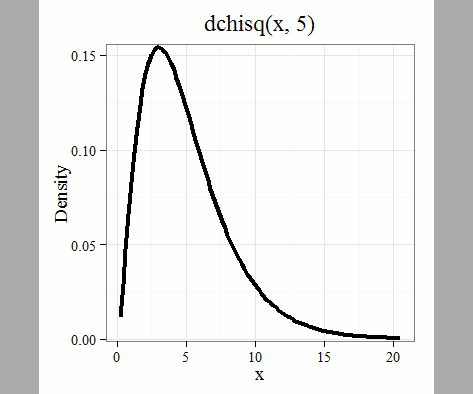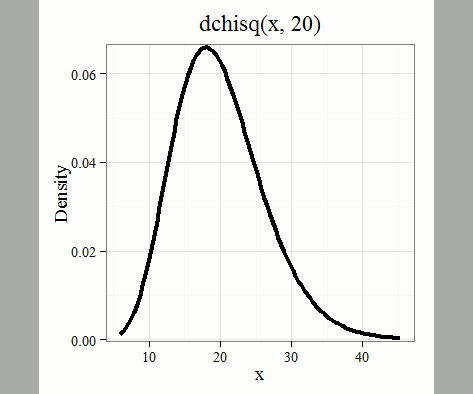
Figure 1. Animated GIF of plots of chi-square distribution over range of degrees of freedom.
Note that the distribution is asymmetric, particularly at low degrees of freedom. Thus tests using the chi-square are one-tailed (Fig 2).
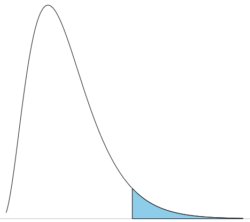
Figure 2. The test of the chi-square is typically one-tailed. In this case, probability of values greater than the critical value.
By convention in the Null Hypothesis Significance Testing protocol (NHST), we compare the test statistic to a critical value. The critical value is defined as the value of the test statistic — the cutoff boundary between statistical significance and insignificance — that occurs at the Type I error rate, which is typically set to 5%. The interpretation of the result is as follows: after calculating a test statistic, we can judge significance of the results relative to the null hypothesis expectation. If our test statistics is greater than the critical value, then the p-value of our results are less than 5% (R will report an exact p-value for the test statistic). You are not expected to be able to follow this logic just yet — rather, we teach it now as a sort of mechanical understanding to develop in the NHST tradition. The justification for this approach to testing of statistical significance is developed in Chapter 8. A portion of the critical values of the chi-square distribution are shown in Figure 3.
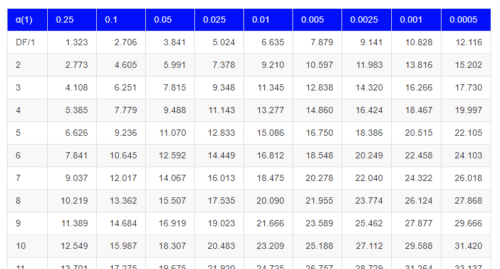
Figure 3. Portion of the table of some critical values of chi-square distribution, one tailed (right-tailed or “upper” portion of distribution).
See Appendix for a complete chi-square table.
The chi-squared test is a one-tailed test.
The result of the calculation of the test statistic is always non-negative because it is calculated by squaring the differences between the observed and expected frequencies. As a consequence, the test is always “right-tailed.”
The chi-square test does not provide information about the direction of an association, nor the strength of the association, only whether or not the variables are independent or associated. We use “correlation,” (eg, Phi coefficient or Cramer’s V, see Chapter 9.1 – Chi-square test: Goodness of fit and Chapter 9.2 – Chi-square contingency tables), to quantify the strength and direction of the association. While statistical significance is important, examining the direction and magnitude, the effect size, provides actionable insight and context for making informed decisions. For example, a new drug tested in a clinical trial may show an association between subject improvement (statistical significance), but yet have a small effect.
Example
Professor Hermon Bumpus of Brown University in Providence, Rhode Island, received 136 House Sparrows (Passer domesticus) after a severe winter storm 1 February 1898. The birds were collected from the ground; 72 of the birds survived, 64 did not (Table 1). Bumpus made several measures of morphology on the birds and the data set has served as a classical example of Natural Selection (Chicago Field Museum). We’ll look at this data set when we introduce Linear Regression.
Table 1. Survival statistics of Bumpus House sparrows
| Yes | No | |
| Female | 21 | 28 |
| Male | 51 | 36 |
Was there a survival difference between male and female House Sparrows? This is a classic contingency table analysis, something we will at length in Chapter 9. For now, we report the Chi-square test statistic for this test was 3.1264 and the test had one degree of freedom. What is the critical value of the chi-square distribution at 5% and one degree of freedom?. Typically we would simply use R to look this up
qchisq(c(0.05), df=1, lower.tail=FALSE)
But we can also get this from the table of critical values (Fig 4). Simply select the row based on the degrees of freedom for the test then scan to the column with the appropriate significance level, again, typically 5% (0.05).
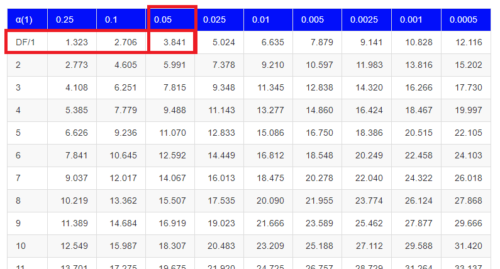
Figure 4. Portion of the chi-square distribution which shows how to find critical value of the chi-square distribution.
For 1 degree of freedom at 5% significance, the critical value is 3.841. Back to our hypothesis: Did male and female survival differ in the Bumpus data set? Following the NHST logic, if the test statistic value (e.g., 3.1264) is greater than the critical value (3.841), then we would reject the null hypothesis. For this example, we would conclude no statistical difference between male and female survival because the test statistic was smaller than the critical value. How likely are these results due to chance? That’s where the p-value comes in. Our test statistic value falls between 5% and 10% (2.706 < 3.1264 < 3.841). In order to get the actual p-value of our test statistic we would need to use R.
R code
Given a chi-square test statistic you can use R to calculate the probability of that value against the null hypothesis. At the R prompt
pchisq(c(3.1264), df=1, lower.tail=FALSE)
And R output
[1] 0.07703368
Because we are using R Commander, simply select the command by following the menu options.
Rcmdr: Distributions → Continuous distributions → Chi-squared distribution → Chi-squared probabilities …
Enter the chi-square value and degrees of freedom (Fig 5).
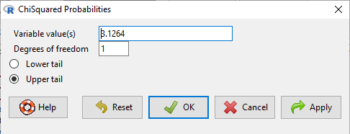
Figure 5. Screenshot of input box in Rcmdr for Chi-square probability values.
Questions
- What happens to the shape of the chi-square distribution as degrees of freedom are increased from 1 to 5 to 20 to 100?
Be able to answer these questions using the Chi-square table, Appendix 20.2, or using Rcmdr
- For probability α = 5%, what is the critical value of the chi-square distribution (upper tail)?
- The value of the chi-square test statistic is given as 12. With 3 degrees of freedom, what is the approximate probability of this value, or greater from the chi-square distribution?
Quiz Chapter 6.9
Chi-square distribution
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate (Z)
- Moments
- Chi-square (Χ2) distribution
- t distribution
- F distribution
- References and suggested readings
6.7 – Normal distribution and the normal deviate (Z)
Introduction
In chapter 3.3 we introduced the normal distribution and the Z score, aka normal deviate, as part of a discussion about how some knowledge about characteristics of the dispersion of our data sampled from a population could be used to calculate how many samples we need (the empirical rule). We introduced Chebyshev’s inequality as a general approach to this problem, where little is known about the distribution of the population and contrasted it with the Z score, for cases where the distribution is known to be Gaussian or the normal distribution. The normal distribution is one of the most important distributions in classical statistics. All normal distributions are bell-shaped and symmetric about the mean. To describe a normal distribution only two parameters are needed: the population mean, μ, and the population standard deviation, σ. The normal distribution with mean equal to zero and standard deviation equal to one is called the standard normal, or Z distribution. With use of the Z score any normal distribution can be quickly converted to the standard normal distribution.
Proportions of a Normal Distribution
This concept will become increasingly important for the many statistical tests we will learn over the next few weeks. What is the proportion of the populations that is greater than some specific value? Below (Fig 1), again, I have generated a large data set, now with population mean µ = 5 and σ = 2. The red line corresponds to the equation of the normal curve using our values of µ = 5 and σ = 2.

Figure 1. Frequency of observations expected to be greater than 7 (red bars) from a large population with mean µ = 5 and σ = 2.
R code for Fig 1.
set.seed(123) myData <- rnorm(1000, mean = 5, sd = 2) h <- hist(myData, breaks = 20, plot = FALSE) threshold <- 7 # Bars with midpoints greater than threshold will be "red", # and others will be "white." bar_colors <- ifelse(h$mids > threshold, "red", "white") plot(h, col = bar_colors, xlab = "Value", ylab = "Frequency")
Note that this is a crucial step! We assume that our sample distribution is really a sample from a population density (= “area under the curve”) function (= “an equation”) for a normal random (= “population”) variable.
Once I (you) make this assumption, then we have powerful and easy to use tools at our command to answer questions like
Question: What proportion of the population is greater than 7 (Fig 1, colored in red)?
This gets to the heart of the often-asked question, How many samples should I measure? If we know something about the mean and the variability, then we can predict how many samples will be of a particular kind. Let’s solve the problem.
The Z score
We could use the formula for the normal curve (and a lot of repetitions), but fortunately, some folks have provided tables that short-cut this procedure. R and other programs also can find these numbers because the formulas are “built in” to the base packages. First, let’s introduce a simple formula that lets us standardize our population numbers so that we can use established tables of probabilities for the normal distribution.
Below, we will see how to use Rcmdr for these kinds of problems.
However, it’s one of the basic tasks in statistics that you should be able to do by hand. We’ll use the Z score as a way to take advantage of known properties of the standard normal curve.

Z = 1 (with the mean and SD). Z (say “Z-score”) is called the normal deviate (aka “standard normal score”; it is also called the “Z-score”); it gives us a shortcut for finding the proportion of data greater than 7 in this case).
We use the normal deviate to do a couple of things; one use is to standardize a sample of observations so that they have a mean of zero and a standard deviation of one (the Z distribution). The data would then said to have been normalized.
The second use is to make predictions about how often a particular observation is likely to be encountered. As you can imagine, this last use is very helpful for designing an experiment — if we need to see a specified difference, we can conduct a pilot study (or refer to the literature) to determine a mean and level of variability for our observation of choice, plug these back into the normal equation and predict how likely we can expect to see a particular difference. In other words, this is one way to answer that question — how many observations need I make for my experiment to be valid?
Table of normal distribution
A portion of the table of the normal curve is provided at our web site and in your workbook. For our discussions, here’s another copy to look at (Fig 2).
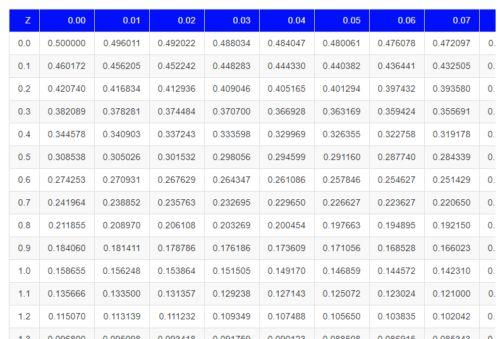
Figure 2. Portion of the table of the normal distribution. Only values equal to or greater than Z = 0 are visible.
See Table 1 in the Appendix for a full version of the normal table.
We read values of Z from the first column and the first row. For Z = 0.23 we would scan the top row, scoot over to fourth column, then trace to where the row and column intersect (Fig 3); the frequency of occurrence of values at Z = 0.23 is 0.409046 or 40.9% (Fig 3).
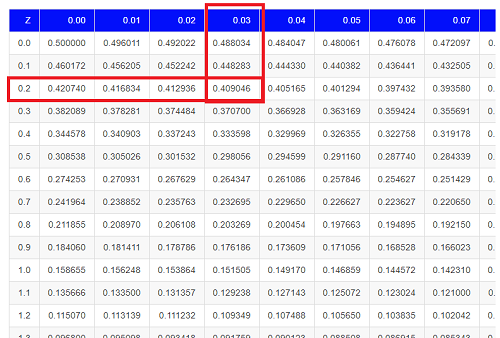
Figure 3. Highlight Z = 0.23, frequency is 0.409046.
Z on the standard normal table is going to range between -4 and +4, with Z = 0 corresponding to 0.500. The Normal table values are symmetrical about the mean of zero.
What to make of the values of Z, from -4, -3, … +2, +3, up to +4 and beyond? These are the standard deviations! Recall that using the Z score you corrected to mean of zero (got it!), and a standard deviation of one! A Z of 2 is twice the standard deviation; a Z = 3 is therefore three times the standard deviation, and so forth. The distribution is symmetrical: you get the same frequency for negative as for positive values. So on the “X” axis on a standard normal distribution, we have units of standard deviation plus (greater) or minus (less) than the mean. In Figure 4, area less than -1 standard deviations is highlighted (Fig 4).
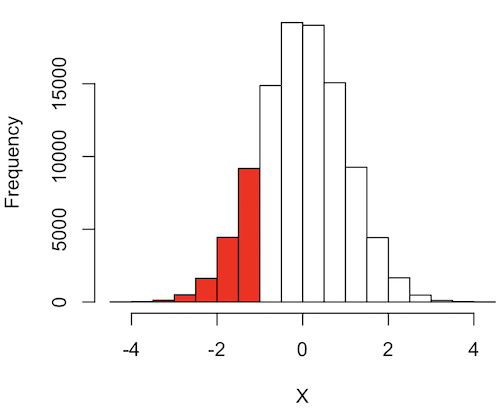
Figure 4. Plot of standard normal distribution; area less than -1 σ.
R code for Fig 4.
set.seed(123) myData2 <- rnorm(100000, mean = 0, sd = 1) threshold <- -1 bar_colors <- ifelse(h$mids < threshold, "red", "white") # Additional code used, same as Figure 1.
Question. How many multiples of standard deviations would you have for a Z score of Z = 1.75?
Answer = 1.75 times
Examples
See Table 1 in the Appendix for a full version of the normal table as you read this section.
What proportion of the data set will have values greater than 7? After applying our Z score equation, I get Z = 1.0 and for a Z of 1.0 = 0.1587 or 15.87% of the observations are greater than 7.
What proportion of the data set will have values less than -7? After applying our Z score equation, I get Z = -1.0. Taking advantage of symmetry argument, I just take my Z = -1.0 and make it positive — instead of values smaller than -1.0 we now have values greater than +1.0. And for a Z of 1.0 = 0.1587 or 15.87% of the observations are greater than 7, which means that 15.87% will be -7 or smaller.
What proportion of the data set will have values greater than 8? Again, apply the Z score equation I get Z of 1.5 = 0.0668 or 6.68% of the observations are greater than Z.
What proportion of the population is between 5 and 7 ? (colored in red). Draw the problem (example shown in Fig 5).
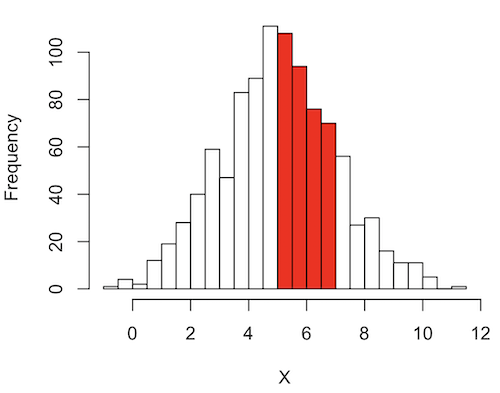
Figure 5. Proportion of the population is between 5 and 7.
R code for Fig 5.
# Used myData from Fig 1 code.
highlight_start <- 5
highlight_end <- 7
bar_colors <- rep("white", length(h$counts))
bar_colors[h$breaks[-length(h$breaks)] >= highlight_start & h$breaks[-1] <= highlight_end] <- "red"
# Additional code used, same as Figure 1.
Note 1: h$breaks[-length(h$breaks)] gives the left edges of the bins, and h$breaks[-1] gives the right edges.
Worked problem
1 – (proportion beyond 7) – (proportion less than 5)
1 – (0.1587) – (proportion less than 5)
And the proportion less than 5?
Use Z-score equation again. Now we find that
Z = 0
And look up Z of 0 from the table = 0.5 proportion or 50.0%
Therefore, the proportion between 5 & 7 equals
1 -0.1587 – 0.50 = 0.3413
Answer = 34.13 % of the observations are between 5 and 7 when the mean µ = 5 and s = 2.
Questions
Several questions were asked in the text.
1. Proportion of observations greater than 7 from a large population with mean µ = 5 and σ = 2.
2. How many multiples of standard deviations would you have for a Z score of Z = 1.75?
3.
Quiz Chapter 6.7
Normal distribution questions
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and probabilities
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate (Z)
- Moments
- Chi-square (Χ2) distribution
- t distribution
- F distribution
- References and suggested readings
6.6 – Continuous distributions
Large numbers and the Central Limit Theorem
Imagine we’ve collected (sampled) data from a population and now want to summarize the data sample. How do we proceed? A good starting point is to plot the data in a histogram and note the shape of the sample distribution. Not to get too far ahead of ourselves here, but much of the classical inferential statistics demands that we are able to assume that the sampled values come from a certain kind of distribution called the normal, or Gaussian distribution.
Consider a random sample drawn from a normally distributed population of the following series of graphs, Figures 1 – 4:
Figure 1. Sample size = 20, drawn from population with known μ = 0 and σ = 1.
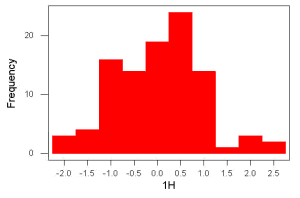
Figure 2. Sample size = 100, also drawn from population with known μ = 0 and σ = 1.
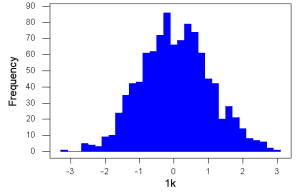
Figure 3. Sample size n = 1000, once again drawn from population with known μ = 0 and σ = 1.
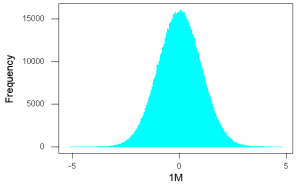
Figure 4. And lastly, sample size n = 1 million also drawn from population with known μ = 0 and σ = 1.
These graphs illustrate a fundamental point in statistics: for many kinds of measurements in biology, the more data you sample, the more likely the data will approach a normal distribution. This series of simulations was a quick and dirty “proof” of the Central Limit Theorem, which is one of the two fundamental theorems of probability, the other being that of Law of Large Numbers (i.e., large-sample statistics). Basically the CLT says that for a large number of random samples, the sample mean will approach the population mean, μ, and the sample variance will approach the population variance σ2; the distribution of the large sample will converge on the normal distribution.
As the sample size gets bigger and bigger, the resulting sample means and standard deviations get closer and closer to the true value (remember — I TOLD the program to grab numbers from the Z distribution with a mean of zero and standard deviation = 1), obeying the Law of Large Numbers.
Simulation
I used the computer to generate sample data from a population. This process is called a simulation. R can make new data sets by sampling from known populations with specified distribution properties that we determine in advance — a very powerful tool — a technique used for many kinds of statistics (e.g., Monte Carlo methods, bootstrapping, etc., see Chapter 19).
Note 1: How I got the data. All of these data are from a simulation where I asked told R, “grab random numbers from an infinitely large population, with mean = 0 and standard deviation = 1.”
- The first graph is for a sample of 20 points;
- the second for 100;
- the third for 1,000;
- and lastly, 1 million points.
To generate a sample from a normal population, the Rcmdr call the menu by selecting:
Rcmdr: Distributions → Continuous distributions → Normal distribution → Sample from normal distribution…
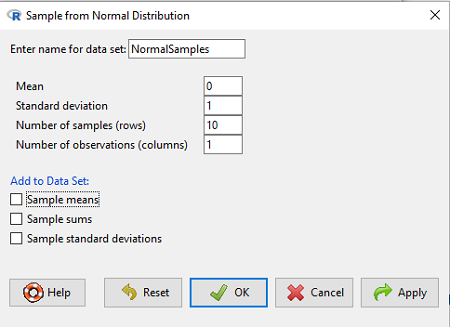
Figure 5. Screenshot Rcmdr menu, sample from a normal distribution.
The menu pops up. I entered Mean (μ) = 0 and Standard deviation (σ) = 1 number of samples = 10, unchecked all boxes under the “add to data set.” I left the object name as “NormalSamples,” you can, of course, change it as needed. R code derived from these requests were
normalityTest(~obs, test="shapiro.test", data=NormalSamples)
NormalSamples <- as.data.frame(matrix(rnorm(10*1, mean=0, sd=1), ncol=1))
rownames(NormalSamples) <- paste("sample", 1:10, sep="")
colnames(NormalSamples) <- "obs"
This results in a new data.frame called NormalSamples with a single variable called obs.
Note 2: About pseudorandom number generator, PRNG. An algorithm is used for creating a sequence of numbers that are like random numbers. We say “like” or “pseudo” random numbers because the algorithm requires a starting number called the seed, rather than a truly random process, i.e., a source of entropy outside of the computer. The default PRNG algorithm in base R is Mersenne Twister (Wikipedia), though there are many others included in base R (bring up the help menu by typing ?RNGkind at the prompt), as well as other packages, like random, which can be used to generate truly random numbers (source of entropy is “atmospheric noise,” per citation in the package, see also random.org).
rnorm() was the function used to sample from a normal distribution. If you run the function over and over again (e.g., use a for loop), each time you will get different samples. For example, results from three runs
for (i in 1:3){
print(rnorm(5))
}
[1] -0.4221672 -1.4317800 -1.8310352 0.4181184 -1.1596058
[1] -0.2034944 1.1809083 1.5925296 -2.0763677 1.6982357
[1] -1.0967218 -0.3205041 -1.7513838 -0.3335311 -1.8808454
However, if you set the seed to the same number before calling rnorm, you’ll get the same sampled numbers.
for (i in 1:3){
set.seed(1)
print(rnorm(5))
}
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
The seed number can be any number, it does not have to equal 1.
After creating a sample of numbers drawn from the normal distribution, make a histogram, Rcmdr: Graphs → Histogram… (see Chapter 4.2).
The normal distribution
More on the importance of normal curves in a moment. Sometimes people call these “bell-shaped” curves. You may also see such distributions referred to as Gaussian Distributions, but the normal curve is but one of many Gaussian -type distributions. Moreover, not all “bell-shaped” curves are NORMAL. For a distribution to be “normally distributed” it must follow a specific formula.

This formula has a lot of parts, but once we break down the parts, we’ll see that there is just two things to know. First, let’s identify the parts of the equation:
 is the height of the curve (normal density)
is the height of the curve (normal density)
 (pie) is a constant = 3.14159… (R, use
(pie) is a constant = 3.14159… (R, use pi)
µ is the population mean
σ2 is the population variance
σ is the square-root of the variance or the population standard deviation
e is the natural logarithm (R, use exp())
 is the individual’s value
is the individual’s value
Why the Normal distribution is so important in classical statistics
With these distinctions out of the way, the first important message about the normal curve is that it permits us to say how likely (i.e., how probable) is a particular value if the observation comes from a population with mean µ and standard deviation σ and the population from which the sample was drawn came from a normal distribution.
The second message: all we need to know to recreate the normal distribution for a set of data is the mean and the variance (or the standard deviation) for the population!! With just these two parameters, we can then determine the expected proportion of observations expected for each value of X. Note — we generally do not know these two because they are population parameters: we must estimate them from samples, using our sample statistics, and that’s where the first big assumption in conducting statistical analyses comes into play!!
An example for calculating the normal distribution when knowing the mean and variance
µ = 5, σ2 = 10 (thus, the standard deviation, σ = 3.16)
The formula becomes

Now, plug in different values of X (for example, what’s the probability that a value of X could be 0, 1, 2, …, 10? If we really do have a normal curve with mean = 5, and variance = 10).
The normal equation returns the proportion of observations in a normal population for each X value:
When i = 5 Y5 = 0.12616 This is the proportion of all data points that have an X = 5 When i = 1 Y1 = 0.019995 This is the proportion of all data points that have an X = 1
We can keep going, getting the proportion expected for each value of X, then make the plot (Fig 6).
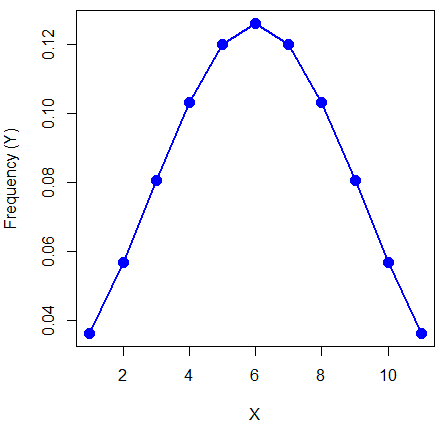
Figure 6. Frequency expected for a few points (X: 0 – 10) drawn from a normal distribution, calculated using the formula and example values.
Here’s the R code for the plot
X = seq(0,10, by=1) Y = (0.398947/3.16)*exp((-1*(X-5)^2)/20) plot(Y~X, ylab="Frequency (Y)", cex=1.5, pch=19,col="blue") lines(X,Y, col="blue", lwd=2)
Next up, more about the normal distribution, Chapter 6.7.
Questions
- For a mean of 0 and standard deviation of 1, apply the equation for the normal curve for X = (-4, -3.5, -3, -2.5, -2, -1.5, -1, -0.5, 0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4). Plot your results.
- Sample from a normal distribution with different sample size, means, and standard deviations, each time make a histogram and compare the shape of the histograms.
- For a subset of
Quiz Chapter 6.6
Continuous distributions
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings
6.5 – Discrete probability distributions
Binomial distribution
Discrete refers to particular outcomes — data that take on only specific separate values. Discrete data types include all of the categorical types we introduced earlier, including binary, ordinal, and nominal.
The binomial probability distribution is a discrete distribution for the number of successes, k, in a sequence of n independent trials, where the outcome of each trial can take on only one of two possible outcomes. For cases of 0 or 1, yes or no, “heads” or “tails,” male or female, pass or fail, we talk about the binomial distribution, because the outcomes are discrete and there can be only two possible (binary) outcomes.
Note 1: The biological definition of sex is binary — whether sexually reproducing organism produces male (sperm) or female (ovum) gametes (cf discussion in Goymann et al 2022). For the argument that sex is a continuum held by some biomedical and social scientists, see Ainsworth 2015.
The mathematical function of the binomial is written as
![\begin{align*} Pr\left [ X \ successes \right ] = \binom{n}{X} p^X \left ( 1-p \right )^{n-X} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-3a30d36f8ba1b9fcf3a671be2674d444_l3.png "Rendered by QuickLaTeX.com")
where the binomial coefficient is given by

and X refers to the number of ways to choose “success” from n observations.
Consider an example.
We have to define what we mean by success. For coin toss, this might be the number of heads.
The mean for the binomial this is given simply as

where X is “Heads” (the category of successes for our example), and p corresponds to the probability the selected event occurs, in this case, “Heads.”
The variance of the binomial distribution is given by

Here’s a density plot of two trials with success 2% with n (x) equal to 20 (Fig 1).
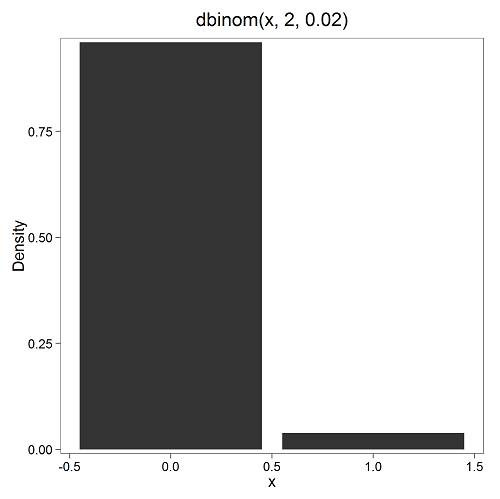
Figure 1. Plot generated with KMggplot2 Rcmdr plugin.
Here’s the R code
Create the trials, 1 through 20, then create an object to hold the number of trials
nSize=1:20 Size <- length(nSize); Size
R returns
[1] 20
Assign the probability value to an object
prob <- 0.02
Next, calculate the mean, mu, and the variance, var, for the binomial with prob = 0.02 and number of trials Size = 20
mu <- Size*prob var <- Size*prob*(1-prob)
Print the mean and variance; lets assign them to an object then print the object
stats <- c(mu, var); stats
And R returns
[1] 0.400 0.392
And here’s a real-world example. Twinning in humans is rare. In Hawaiʻi in the 1990’s the rate of twin births (monozygotic and dizygotic) was about 20 for every 1000 births or 2%. “Success” here then is twin births.
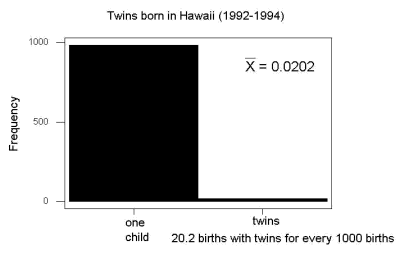
Figure 2. Example of binomial-like distribution: reported twins born in Hawaiʻi.
Interestingly, rates of twins have since increased in Hawaiʻi (31 out of 1000 births) and in the United States overall (33 out of 1000 births) (Table 2, NCHS Data Brief No. 80, 2012). Data for Fig 2 were for year 2009.
Out of ten births, what is the probability of two twin births in Hawaiʻi?
![\begin{align*} Pr\left [ 2 \ twinbirths \right ] = \left ( \frac{10}{2} \right ) 0.031^2 \left ( 1 - 0.031 \right )^{10-2} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-65965fd393d815506757b84eda02c026_l3.png "Rendered by QuickLaTeX.com")
You can solve this with your calculator (yikes!), or take advantage of online calculators (GraphPad QuickCalcs), or use R and Rcmdr.
In R, simply type at the prompt
dbinom(2,10,0.031) [1] 0.03361446
Try in R Commander.
Rcmdr → Distributions → Discrete distributions → Binomial distribution → Binomial probabilities …

Figure 3. Rcmdr menu to get binomial probability.
Note I used p = 0.033 the rate for entire USA. Here’s the output
> .Table <- data.frame(Pr=dbinom(0:10, size=10, prob=0.033)) > rownames(.Table) <- 0:10 > .Table Pr 0 7.149320e-01 1 2.439789e-01 2 3.746728e-02 ← Answer, 0.0375 or 3.75% 3 3.409639e-03 4 2.036263e-04 5 8.338782e-06 6 2.371422e-07 7 4.624430e-09 8 5.918028e-11 9 4.487991e-13 10 1.531579e-15
And here is the output for our example from Hawaiʻi (p = 0.031).
> .Table <- data.frame(Pr=dbinom(0:10, size=10, prob=0.031)) > rownames(.Table) <- 0:10 > .Table Pr 0 7.298570e-01 1 2.334940e-01 2 3.361446e-02 ← Answer, 0.0336 or 3.36% 3 2.867694e-03 4 1.605494e-04 5 6.163507e-06 6 1.643178e-07 7 3.003893e-09 8 3.603741e-11 9 2.561999e-13 10 8.196283e-16
We use the binomial distribution as the foundation for the binomial test, ie, the test of an observed proportion against an expected population level proportion in a Bernoulli trial.
Hypergeometric distribution
The binomial distribution is used for cases of sampling with replacement from a population. When sampling without replacement is done, the hypergeometric distribution is used. It is the number of successes, k, in a sequence of n independent trials drawn from a fixed population.
Note 2: A fixed population in epidemiology refers to a group of individuals, defined by set of characteristics. Examples include individuals selected because they all share a common life event, eg, giving birth. The population is “fixed” because, once an individual is included in the population, they remain a member of the population even if their characteristics change during the duration of the study. The opposite of a fixed population is an dynamic or open population. Definitions from Chapter 2 in Aschengrau and Seage (2003).
This sampling scheme means that each draw is no longer independent — with each draw you decrease the remaining number of observations and thus change the proportion.
The P-value from the hypergeometric distribution is often used to study if genes from a list of Gene Ontology (eg, biological process functional terms like “cell cycle,” or “apoptosis”) are enriched in the sets of genes with expression differences across the treatment groups (cf, discussion in Cao and Zhang 2014). The R package gprofiler2, which links to a Cloud service at g:Profiler, the can be used to do gene enrichment analyses with stunning visualizations (eg, Manhattan plot) suitable for publication.
The mathematical function of the hypergeometric is written as
![\begin{align*} Pr\left [X = k \right ] = \frac{\left ( \frac{K}{k} \right )\left ( \frac{N - K}{n - k} \right )}{\left ( \frac{N}{n} \right )} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-4c3fda04d51bcfab12f92b7cd77ff0ad_l3.png "Rendered by QuickLaTeX.com")
where N is the population size, K is the number of successes in that population, and n and k are defined as above. Lets look apply this to the twinning problem.
In 2009, 2200 women gave birth in Hawaiʻi County, Hawaiʻi. Out of 10 births, what is the probability of 2 twin births in Hawaiʻi?
Assuming “risk” of twinning is the same rate as in rest of USA, then we have expected 72 successes in this population (0.033 * 2200).
Here’s the graph (Fig 4).
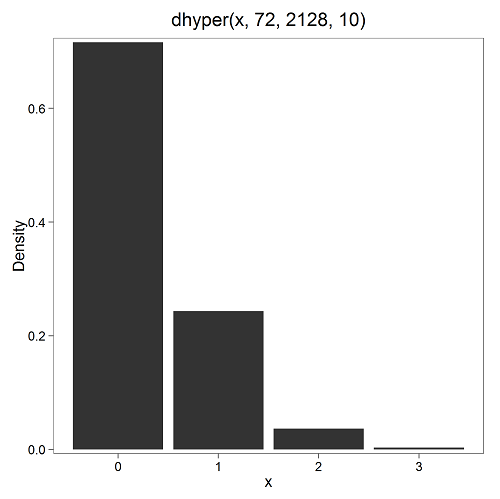
Figure 4. Plot of hypergeometric distribution twinning Hawaiʻi.
where the X axis values shows the number of events with successes (twin births). Taking the bin 2 (we wanted to know about probability of 2 out of ten), we can draw a line back to the Y-axis to get our probability — looks like about 5% roughly. Plot drawn with KMggplot2
To get the actual probability,
Rcmdr → Distributions → Discrete distributions → Hypergeometric distribution → Hypergeometric probabilities …
Figure 5. Rcmdr menu to get hypergeometric probability.
where m is the number of successes, n is the number of “failures,” and k is the number of trials.
> .Table Pr 0 0.716453457 1 0.243438645 2 0.036688041 ← Answer, 0.0367 or 3.67% 3 0.003228871
The reference to white and black balls and urns is a device described by Bernoulli himself and has been used by others ever since to discuss probability problems (called the urn problem) and so I apply it here to be consistent. The urn contains a number of white (x) and a number of black (y) balls mixed together. One ball is drawn randomly from the urn — what color is it? The ball is then is either returned into the urn (replacement) or it is left out (without replacement) as in the hypergeometric problem, and the selection process is repeated.
Besides applications in gambling and balls-in-urns problems, this distribution is the basis for many tests of gene enrichment from microarray analyses. The hypergeometric forms the basis of the Fisher Exact test (see Chapter 9.5).
Discrete uniform distribution
For discrete cases of “1,” “2,” “3,” “4,” “5,” or “6,” on the single toss of fair dice, we can talk about the discrete uniform distribution because all possible outcomes are equally likely. If you are branded as a “card-counter” in Las Vegas, all you’ve done is reached an understanding of the uniform distribution of card suits!
One biological example would be the fate of a random primary oocyte in the human (mammal) female — three out of four will become polar bodies, eventually reabsorbed, whereas one in four will develop into a secondary oocyte (egg); the uniform distribution has to do with the counts of the products — each of the four primary oocytes has the same (apparently) chance (25%) of becoming the egg (Edwards and Beard 1997).
Analyses in biological research often use a uniform distribution as a baseline or null model (Gotelli and Ulrich 2011). For DNA sequencing, the uniform distribution provides a baseline for assessing coverage bias, eg, GC bias (Ross et al 2013). The uniform distribution underlies the Jukes–Cantor evolutionary model. The Jukes–Cantor model assumes equal substitution rates among all four nucleotides (A, T, C, G) and equal base frequencies (Felsenstein 2003).
The uniform distribution exists also for continuous data types, where every value within a specified interval has equal probability density. For example, DNA shearing during initial library prep for sequencing reactions, breakpoints may be modeled as uniformly distributed along fragment length. Sequence-dependent cleavage bias is concluded when certain DNA fragments or sequences are generated or detected more (or less) frequently than would be expected by chance (Meyer and Liu 2014).
Non-uniform distributions reveal cleavage bias.
Poisson distribution
An extension from the binomial case is that, rather than following success or failure, you may have the following scenario. Consider a wind-dispersed seed released from a plant. If we markup the area around the plant in grids, we could then count the number of seeds within each grid. Most grids will have no seeds, some grids will have one seed, a few grids may have two seeds, etc. Multiple seeds in grids is a rare event. The graph might look like
Figure 6. Example, poisson-like graph: the number of wind-dispersed seeds within each grid.
In molecular biology, use of Poisson distribution is common. In digital PCR for example, a DNA sample is diluted and divided into thousands of small reaction volumes or partitions. Thus, each partition contains either zero molecules, one molecule, or more than one molecule, where the loading of molecules into partitions is assumed to be independent, random, and rare per partition. In sequencing, Poisson models are used to describe random sampling of molecules and reads, especially when coverage is generated by non-deterministic processes like shotgun sequencing.
The Poisson has interesting properties, one being that the expected mean, λ, is equal to the variance. Lambda is, with respect to the Poisson distribution, the average number of times an event happens over a specific period or area.
An equation is
![\begin{align*} Pr\left [X\right ] = \frac{\mu^X e^{-\mu}}{X!} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-b172e19511712bb9114f43372f907b6c_l3.png "Rendered by QuickLaTeX.com")
where μ is the mean (or could substitute with variance!), e is the natural logarithm, and X is number of successes you are interested in. For example, if μ = 1, what is the probability of observing a grid with five seeds? Simple enough to do this by hand, but let’s use Rcmdr instead. Here’s the graph (Fig 7) from Rcmdr (KMggplot2 plugin).
Figure 7. The probability of observing a grid with five seeds, poisson μ = 1 (ggplot2).
and for the actual probability we have from R
dpois(5, lambda = 1) [1] 0.003065662
Rcmdr → Distributions → Discrete distributions → Poisson distribution → Poisson probabilities … (Fig 8)
The only thing to enter is the mean (some call μ lambda with symbol λ).
Figure 8. Rcmdr menu, poisson probability.
Here’s the output from R. For intervals 0, 1, 2, 3, …, 6 (Rcmdr just enters this range for you!
> .Table <- data.fram(Pr=dpois(0:6, lambda = 1)) > rownames(.Table) <- 0:6 > .Table Pr 0 0.3678794412 1 0.3678794412 2 0.1839397206 3 0.0613132402 4 0.0153283100 5 0.0030656620 ← Answer, 0.0307 or 3.07% 6 0.0005109437
Next — Continuous distributions
And finally, for ratio (continuous) scale data, which can take on any value, we can express the chance that probability of a given point as a continuous function, with the normal distribution being one of the most important examples (there are others, like the F-distribution). Many statistical procedures assume that the data we use can be viewed as having come from a “normally distributed population.” See Chapter 6.6.
Questions
1.2. Quarterback sacks by game for the NFL team Seahawks, years 2011 through 2022 are summarized below (data extracted from https://www.pro-football-reference.com/ ).
| Sacks | How many games? |
| 0 | 25 |
| 1 | 46 |
| 2 | 49 |
| 3 | 39 |
| 4 | 25 |
| 5 | 14 |
| 6 | 8 |
| 7 | 2 |
| 8 | 1 |
| 9 | 0 |
a) Assuming a Poisson distribution, what are the mean (lambda) and variance?
b) The table covers a total of 112 games. How many sacks (events) were observed?
c) What is the probability of the Seahawks getting zero sacks in a game (in 2022, a season was 17 games; prior years a season was 16 games)?
Quiz Chapter 6.5
Discrete probability
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings
6.4 – Types of probability
Introduction
By probability, we mean a number that quantifies the uncertainty associated with a particular event or outcome. If an outcome is certain to occur, the probability is equal to 1; if an outcome cannot happen, the probability is equal to zero. Most events we talk about in biology have probability somewhere in between.
A basic understanding, or at least an appreciation for probability is important to your education in biostatistics. Simply put, there is no certainty in biology beyond simple expectations like Benjamin Franklin’s famous quip about “death and taxes…”
Discrete probability
You are probably already familiar with discrete probability. For example, what is the probability that a single toss of a fair coin will result in a “heads?” The outcomes of the coin toss are discrete, categorical, either “heads” or “tails.”
Note 1: Obviously, this statement assumes a few things — coin tossed not in a vacuum, for example. We assume a fair coin — equal chance heads or tails. Fair coins have two sides; tossing a coin we expect “heads” or “tails,” but rarely, some coin types may land and come to rest on edge or side (eg, USA nickels). We still consider the coin toss having binary outcomes, by definition, even though a coin may land on edge about one toss in six thousand (Murray and Teare 1993) because the exception is extremely rare. h/t Dr. Jerry Coyne.
And for ten tosses of the coin? And more cogently, what is the probability that you will toss a coin ten times and get all ten “heads?” While different in tone, these are discrete outcomes. An important concept is independence. Are the multiple events independent? In other words, does the toss of coin on the first attempt affect the toss of the coin on the second attempt and so on up to the tenth toss? At least in principle the repeated tosses are independent so to find the probability you just multiply each event’s probability to get the total.
In contrast, if one or more events are not independent but somehow influence the behavior of the next event, then you add the probabilities for each dependent event. We can do better than simply multiply or add events one at a time; depending on the number of discrete outcomes it is very likely that someone has already calculated all possible outcomes and come up with an equation. In the case of the tossing of two coins this is a binomial equation problem and repeat tosses can be modeled by use of the Bernoulli distribution.
Now, try this on for size. What is the probability that the next child born at Kapiolani Medical Center in Honolulu will be assigned female?
We just described a discrete random variable, which can only take on discrete or “countable” numbers. This distribution of values is the probability mass function. The probability of a one fatal airline accident in a year exactly on 20.1 is practically zero (the area under a point along the curve is zero), so we can get the probability of a range of values around the point as our answer.
Continuous probability
Many events in biology are of degree, not kind. It is kind of awkward to think about it, but for a sample of adult house mice drawn from a population, what is the probability of obtaining a mouse that is 20.0000 grams (g) in weight? Each possible value of body mass for a mouse is considered an event, just like in our example of tossing a coin. But clearly, we don’t expect to get a lot of mice that are exactly 20.0000 g in weight. For variables like body mass, the type of data we collect is continuous, and the probability values need to be rethought along a continuum of possible values and, in turn, how likely each value is for a mouse. Although it is theoretically possible that a mouse could weigh ten pounds, we know by experience that this is impossible. Adult mice weigh between 15 and 50 g or there about.
We just described a continuous random variable, which can take on any value between a specific interval of values. This distribution of values is the probability density function (PDF). The probability of a mouse’s weight falling exactly on 20.1 is practically zero (the area under a point along the curve is zero), so we can get the probability of a range of values around the point as our answer.
In statistical inference, following our measurements of the variables from our sample drawn from a population, we make conclusions with the following kind of caveat: “the mean body mass for this strain of mouse is 20 g.” That is our best estimate of the mean (middle) for the population of mice, more specifically, for the body mass of the mice. Here, the variable body mass is more formally termed a random variable. This implies that there is in fact a true population mean body mass for the mice and that any deviations from that mean are due to chance.
In statistics we don’t settle for a single point estimate of the population mean. You will find most reporting of estimates of random variables is accompanies by a statement like, the mean was 20g with a 95% probability that the true population mean is between 18.9 and 21 g. This is called the 95% confidence interval for the mean and it takes into account how good of an estimate our sample is likely to be relative to the true population value. Not only are we saying that we think the population mean is 20g, but we’re willing to say that we are 95% certain that the true value must be between a lower limit (18.9 g) and and upper limit (21 g). In order to make this kind of statement we have to assume a distribution that will describe the probability of mouse weights. For many reasons we usually assume a normal distribution. Once we make this assumption we can calculate how probable a particular weight is for a mouse.
We introduced how to calculate Confidence Intervals in Chapter 3.4 and will extend this in any chapter that introduces an estimation.
Types of probability
To begin refining our concept of probability, it is sometimes useful to distinguish among kinds of probabilities:
- between theoretical and empirical;
- between subjective and objective.
In most cases, including your statistics book, we would begin our discussion of probability by talking of some probabilities for events we’re familiar with.
- The theoretical probability of heads appearing the next time you flip a fair coin is 1/2 or 50%. As long as we’re talking about a fair coin, the probability of a heads appearing each time you flip the coin remains 50%. We can check this by conducting and experiment: out of 10 tosses, how many heads appear? The answer would be an empirical probability, and we understand the chance in an objective manner (no interpretation needed).
- The theoretical probability that a “5” will appear on the face of a fair dice after a toss is 1/6 or 16.667%. Again, as long as we’re talking about a fair dice, the probability of a “5” appearing each time you roll the dice remains 16.667%.
- The probability that at birth, a human baby’s sex will be male about 1/2 or 50%. This is an empirical probability based on millions of observations. Changes in technology, and ethical standards notwithstanding, the probability will remain the same.
- The probability of the birth of a Downs syndrome baby is 1/800, but increases with age until by age 45, the chance is 1/12. Again, these are empirical and objective.
- The probability of winning the Publisher’s Clearing House Sweepstakes is about 1 in 100 million. This probability is theoretical, it is also objective; however, by adding lots of twists to the game, by having multiple opportunities and by giving the appearance that a person must purchase a magazine, some players perceive their chances as increasing or decreasing by their efforts (=subjective).
R and distributions
R offers access to many named distributions. R generally provides four functions available for each.
density (d):the probability density function (PDF) for continuous distributions or the probability mass function (PMF) for discrete distributions.
probability (p): the cumulative distribution function (CDF), which is the chance (probability) of a random variable being less than or equal to a given value
quantile (q): the quantile function (inverse CDF), which returns the value at a given probability
r: draw random numbers from the specified distribution.
Examples of functions for the normal distribution then, are: dnorm(), pnorm(), qnorm(), and rnorm().
Coding example: Find the PDF for x = 0 in a standard normal distribution. # Find the PDF value for x = 0 in a standard normal distribution (mean=0, sd=1)
dnorm(x = 0, mean = 0, sd = 1)
R output
0.398942280401433
Thus, we conclude the chance that x = 0 is about 40%.
Note 2: Technically it’s not the chance that x is exactly 0 — it refers to the chance that the random variable falls within fractionally small interval around that value. That’s the calculus foundation for probability speaking.
Coding example: Find the probability that for x is equal to -1.2 or less in a standard normal distribution.
pnorm(q = -1.2, mean = 0, sd = 1, lower.tail = TRUE)
R output
0.115069670221708
Thus, we conclude the chance that x is equal to or less than -1.2 is about 11.5%.
Coding example: Assuming normal distribution of test scores, what score will 50% of students score? Find the probability that for x is equal to -1.2 or less in a standard normal distribution.
qnorm(0.5, mean = 75, sd = 10)
R output
75
As expected, at 50% it returns the mean. Now, confirm that the lower 25% and upper 75% are 68.26 and 81.75, respectively.
Last coding example, draw random sample of three scores from the same exam.
rnorm(3, mean = 75, sd = 10)
R output
-
66.0384856946112
-
69.1887923903669
-
77.6342297053815
R Commander: Distributions menus give four options
- Quantiles
- Probabilities
- Plot
- Sampling
Note 3: Looking for more examples? These kinds of problems are common skill-based questions one finds in any statistics course. Homework 3: Distributions & Probability in Mike’s Workbook for Biostatistics offers several additional examples to work through. Additional examples are provided in Chapter 6.5 and Chapter 6.6.
Questions
1. Define and distinguish, with examples
- discrete and continuous probability
- theoretical and empirical probability
- subjective and objective probability
Quiz Chapter 6.4
Types of probability
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and proportions
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings
6.3 – Combinations and permutations
Introduction
In statistical inference, an important foundational skill is to be able to count the possible outcomes of an experiment — the sample space. For example, when drawing on a sample of individuals for study from specific groups (strata) of a population, combinations may be calculated; where it is unwarranted to assume a particular theoretical probability distribution applies, permutation tests create a reference distribution by calculating all possible values of a test statistic under rearrangements of the observed data.
The simplest place to begin with probability is to define an event — an event is an outcome — a “Heads” from a toss of coin, or the chance that the next card dealt is an ace in a game of Blackjack. In these simple cases we can enumerate how likely these events are given a number of chances or trials. For example, if the coin is tossed once, then the coin will either land “Heads” or “Tails” (Fig 1).

Figure 1. Heads (left) and Tails (right) of a USA Susan B. Anthony dollar.
We can then ask what is the likelihood of ten “Heads” in ten tosses of a fair coin?
And this gets us to some basic rules of probability:
- if successive events are independent, then we multiply the probability
- if events are not independent, then the probability adds
- do we sample without replacement, i.e., an object can only be used once?
- do we sample with replacement, i.e., an object gets placed “back in the deck” and can be used again and again
Combinations and Permutations
Both combinations and permutations pertain to how samples are selected from a population. Combinations are used if the events or objects of the sample are all of the same kind, whereas for permutations, it is implied that the events or objects are not all of the same kind.
Figure 2. A combination lock
Combinations ignore the order of the events; permutations are ordered combinations. For replacement, the formula for permutations is simply 
In the case of the ten “Heads,” in ten successive trials, the probability is  “ten-times” or
“ten-times” or  = 0.0009766 (in R, just type
= 0.0009766 (in R, just type 0.5^10 or (1/2)^10 at the R prompt).
Examples of permutations in biology include,
Given the four nucleotide bases of DNA, adenine (A), cytosine (C), guanine (G), and thymine (T), how many codons are possible?

where the three (3) refers to the codon, three nucleotide genetic code. Codons are trinucleotide sequences of DNA or RNA that correspond to a specific amino acid. For transcription initiation of a protein-coding gene, a key sequence must be present in the promoter region of the gene. In Archaea and Eukaryotes, that sequence is called the TATA box. How often do we expect to find by chance the heptamer (ie, seven bases) TATA box sequence in the human genome?
Note 1: The consensus TATA box sequence, TATAWAW (W can be either Adenine or Thymine, per Standard IUB/IUPAC nucleic acid code). The TATA box is the binding site for transcription factors, particularly the TATA binding protein.

Thus, we would expect at random to find TATA box sequences every 16,384 bases along the genome. For the human genome of 3.3 billion bases then we would expect at random more than 200,000 TATA box consensus sequences.
Another way to put this is to ask how many combinations of ten tosses gets us ten “Heads” then weigh this against all possible outcomes of tossing a coin ten times — how many times do we get zero Heads? Two “Heads”? And so on. This introduces the combinatorial.

where n is the number of choices (the list of events) and r is how many times you choose or trials. The exclamation point is called the factorial. The factorial instructs you to multiply the number over and over again, “down to one.” For example, if the number is 10, then

In R, just type factorial(10) at the R prompt.
factorial(10) [1] 3628800
An example
Consider an extrasensory perception, ESP, experiment. We place photocopies of two kinds of cards, “Queen” and “King,” into ten envelopes, one card per envelope (Fig 2). Thus, an envelope either contains a “Queen” or a “King.”

Figure 2. Playing cards with images commemorating 150th anniversary of Charles Darwin’s Origin of Species. (Design John R. C. White, Master of the Worshipful Company of Makers of Playing Cards 2008 to 2009.)
We shuffle the envelopes containing the cards and volunteers guess the contents of the envelopes, one at a time. We score the correct choices after all envelopes had been guessed. (It’s really hard to set these kinds of experiments up to rule out subtle cues and other kinds of experimental error! Diaconis 1978, Pigliucci 2010, pp. 77 – 83.) By chance alone we would expect 50% correct (e.g., one way to game the system would have been for the volunteer simply to guess “Queen” every time; since we had placed five “Queen” cards the volunteer would end up being right 50%).
What are the possible combinations?
Let’s start with one correct; the volunteer could be right by guessing the first one correctly, then getting the next nine wrong, or equivalently, the first choice was wrong, but the second was correct followed by eight incorrect choices, and so on.
We need math!
Let n = 10 and r = 1
Using the formula above we have

or ten ways to get one out of ten correct. This is the number of combinations without replacement.
In R, we can use the function choose(), included in the base install of R. At the R prompt type
choose(10,1)
and R returns
[1] 10
For permutations, use choose(n,k)*factorial(k).
To get permutations for larger sets, you’ll need to write a function or take advantage of functions written by others and available in packages for R. See gtools package, which contains programming tools for R. There are several packages that can be used to expand capabilities of working with permutations and combinations. For example, install a package and library called combinat and then run the combn() function, together with the dim() function, which will return
dim(combn(10,1))[2] [1] 10
R explained
In the combn() the “10” is the total number of envelopes and the “1” is how many correct guesses. We also used the dim() function to give us the size of the result. The dim() function returns two numbers, the number of rows and the number of columns — combn() returns a matrix and so dim() saves you the trouble of counting the outcomes — the “[2]” tells R to return the total number of columns in the matrix created by combn(). Here’s the output from combn() , but without the dim() function
combn(10,1) [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] 1 2 3 4 5 6 7 8 9 10
in order, we see that there is one case where the success came the first time [1,1], another case where success came on the second try [1,2] and so on.
We can write a simple function to return the combinations
for (many in seq(0, 10, by = 1)){
print(choose(10, many))
}
an inelegant function, but it works well enough, returning
[1] 1 [1] 10 [1] 45 [1] 120 [1] 210 [1] 252 [1] 210 [1] 120 [1] 45 [1] 10 [1] 1
Note that there’s only one way to get zero correct, only one way to get all ten correct.
For completion, what would be the permutations? Use the permn() function (same combinat library) along with length() function to get the number of permutations
length(permn(10)) [1] 3628800
Continue the example
Back to our ESP problem. If we continue with the formula, how many ways to get two correct? Three correct? And so on, we can show the results in a bar graph (Fig. 3).
Figure 3. Bar chart of the combinations of correct guesses out of 10 attempts (graph was presented in Chapter 4.1).
The graph in Figure 3 was made in R
Combos <- seq(0,10, by=1) HowMany <- c(1,10,45,120,210,252,210,120,45,10,1) barplot(HowMany, names.arg = Combos, xlab = "Number correct", ylab = "Count",col = "darkblue")
If you recall, we had two students score eight out of ten. Is this evidence of “ESP?” It certainly seems pretty good, but how rare is this to score 8 out of 10? The total number of outcomes was

Eight out of ten could be achieved in 45 different ways, so

So, eight out of ten is pretty unlikely! Is it evidence for ESP powers in our Biostatistics class? In fact, at the traditional Type I error rate of 5% used in biology and other sciences to evaluate inferences from statistical tests (See Chapter 8), we would say that this observation was statistically significant. Given that this would be an extraordinary claim, this should give you an important clue that statistical significance is not the same thing as evidence for the claim of ESP.
Note 2: This is a good example where frequentist approach may not be the best approach — the Bayesian prior probability for ESP is vanishingly low. See O’Hagan (2006) for a similar ESP problem worked from a Bayesian perspective.
In other words, Is our result biologically significant? Probably not, but I’ll keep my eyes on you, just in case.
Conclusions
Combinations or permutations?
Combinations refers to groups of n things taken k times without repetition. Note that order does not matter, just the combination of things. Permutations, on the other hand, specifically relate the number of ways a particular arrangement can show up.
Questions
- Calculate the combinations, from zero correct to ten correct, from our ESP experiment, i.e., confirm the numbers reported in Figure 3.
- Consider our ESP tests based on guessing cards. Let’s say that one subject repeatedly reports correct guesses at a rate greater than expected by chance. Why or why not should we view this as evidence the person may have extrasensory perception?
- Return to our TATA box example. The number of protein-coding genes in the human genome is presently estimated to be 20,620 (NCBI August 2025). Given that each gene has one promoter sequence, what proportion of TATA boxes are not associated with protein-coding genes?
- Assuming a standard 52-card deck, how many possible 5-card poker hands — the set of cards a player holds during a round of play — are there?
Quiz Chapter 6.3
Combinations and permutations
Chapter 6 contents
- Introduction
- Some preliminaries
- Ratios and probabilities
- Combinations and permutations
- Types of probability
- Discrete probability distributions
- Continuous distributions
- Normal distribution and the normal deviate (Z)
- Moments
- Chi-square distribution
- t distribution
- F distribution
- References and suggested readings