9.1 – Chi-square test: Goodness of fit
Introduction
We ask about the “fit” of our data against predictions from theory, or from rules that set our expectations for the frequency of particular outcomes drawn from outside the experiment. Three examples to illustrate goodness of fit, GOF,  , A, B, and C follow.
, A, B, and C follow.
A. For example, for a toss of a coin, we expect heads to show up 50% of the time. Out of 120 tosses of a fair coin, we expect 60 heads, 60 tails. Thus, our null hypothesis would be that heads would appear 50% of the time. If we observe 70 heads in an experiment of coin tossing, is this a significantly large enough discrepancy to reject the null hypothesis?
B. For example, simple Mendelian genetics makes predictions about how often we should expect particular combinations of phenotypes in the offspring when the phenotype is controlled by one gene, with 2 alleles and a particular kind of dominance.
For example, for a one locus, two allele system (one gene, two different copies like R and r) with complete dominance, we expect the phenotypic (what you see) ratio will be 3:1 (or  round,
round,  wrinkle). Our null hypothesis would be that pea shape will obey Mendelian ratios (3:1). Mendel’s round versus wrinkled peas (RR or Rr genotypes give round peas, only rr results in wrinkled peas).
wrinkle). Our null hypothesis would be that pea shape will obey Mendelian ratios (3:1). Mendel’s round versus wrinkled peas (RR or Rr genotypes give round peas, only rr results in wrinkled peas).
Thus, out of 100 individuals, we would expect 75 round and 25 wrinkled. If we observe 84 round and 16 wrinkled, is this a significantly large enough discrepancy to reject the null hypothesis?
C. For yet another example, in population genetics, we can ask whether genotypic frequencies (how often a particular copy of a gene appears in a population) follow expectations from Hardy-Weinberg model (the null hypothesis would be that they do).
This is a common test one might perform on DNA or protein data from electrophoresis analysis. Hardy-Weinberg is a simple quadratic expansion:
If p = allele frequency of the first copy, and q = allele frequency of the second copy, then p + q = 1,
Given the allele frequencies, then genotypic frequencies would be given by 1 = p2 + 2pq + q2.
Deviations from Hardy-Weinberg expectations may indicate a number of possible causes of allele change (including natural selection, genetic drift, migration).
Thus, if a gene has two alleles,  and
and  , with the frequency for ,
, with the frequency for ,  and for ,
and for ,  (equivalently q = 1 – p) in the population, then we would expect 36
(equivalently q = 1 – p) in the population, then we would expect 36  , 16
, 16  , and 48
, and 48  individuals. (Nothing changes if we represent the alleles as A and a, or some other system, eg, dominance/recessive.)
individuals. (Nothing changes if we represent the alleles as A and a, or some other system, eg, dominance/recessive.)
Question. If we observe the following genotypes: 45 individuals, 34 individuals, and 21 individuals, is this a significantly large enough discrepancy to reject the null hypothesis?
Table 1. Summary of our Hardy Weinberg question
| Genotype | Expected | Observed | O – E |
| aa | 70 | 45 | -25 |
| aa’ | 27 | 34 | 7 |
| a’a’ | 3 | 21 | 18 |
| sum | 100 | 100 | 0 |
Recall from your genetics class that we can get the allele frequency values from the genotype values, eg,

We call these chi-square tests, tests of goodness of fit. Because we have some theory, in this case Mendelian genetics, or guidance, separate from the study itself, to help us calculate expected values in a chi-square test.
Note 1: The idea of fit in statistics can be reframed as how well does a particular statistical model fit the observed data. A good fit can be summarized by accounting for the differences between the observed values and the comparable values predicted by the model.
Note also for our coin toss example, goodness of fit isn’t exactly proper terminology — afterall the test is equal probability of the two outcomes, not whether we have match between an observed distribution and an expected distribution (true statement if we add “follows a binomial distribution”).
 goodness of fit
goodness of fit
For k groups, the equation for the chi-square test may be written as

where fi is the frequency (count) observed (in class i) and fi<hat> is the frequency (count) expected if the null hypothesis is true, sum over all k groups. Alternatively, here is a format for the same equation that may be more familiar to you… ?

where Oi is the frequency (count) observed (in class i) and Ei is the frequency (count) expected if the null hypothesis is true.
The degrees of freedom, df, for the GOF are simply the number of categories minus one, k – 1.
Explaining GOF
Why am I using the phrase “goodness of fit?” This concept has broad use in statistics, but in general it applies when we ask how well a statistical model fits the observed data.
At least for the chi-square test it is simple to see how the test statistic increases from zero as the agreement between observed data and expected data depart, where zero would be the case in which all observed values for the categories exactly match the expected values.
The goodness of fit test is designed to evaluate whether or not your data agree with a theoretical expectation (there are additional ways to think about this test, but this is a good place to start). Let’s take our time here and work with an example. The other type of chi-square problem or experiment is one for the many types of experiments in which the response variable is discrete, just like in the GOF case, but we have no theory to guide us in deciding how to obtain the expected values. We can use the data themselves to calculate expected values, and we say that the test is “contingent” upon the data, hence these types of chi-square tests are called contingency tables.
You may be a little concerned at this point that there are two kinds of chi-square problems, goodness of fit and contingency tables. We’ll deal directly with contingency tables in the next section, but for now, I wanted to make a few generalizations.
- Both goodness of fit and contingency tables use the same chi-square equation and analysis. They differ in how the degrees of freedom are calculated.
- Thus, what all chi-square problems have in common, whether goodness of fit or contingency table problems
- You must identify what types of data are appropriate for this statistical procedure? Categorical (nominal data type).
- As always, a clear description of the hypotheses being examined.
For goodness of fit chi-square test, the most important type of hypothesis is called a Null Hypothesis: In most cases the Null Hypothesis (HO) is “no difference” “no effect”…. If HO is concluded to be false (rejected), then an alternative hypothesis (HA) will be assumed to be true. Both are specified before tests are conducted. All possible outcomes are accounted for by the two hypotheses.
From above, we have
- A. HO: Fifty out of 100 tosses will result in heads.
- HA: Heads will not appear 50 times out of 100.
- B. HO: Pea shape will equal Mendelian ratios (3:1).
- HA: Pea shape will not equal Mendelian ratios (3:1).
- C. HO: Genotypic frequencies will equal Hardy-Weinberg expectations.
- HA: Genotypic frequencies will not equal Hardy-Weinberg expectations
Assumptions: In order to use the chi-square, there must be two or more categories. Each observation must be in one and only one category. If some of the observations are truly halfway between two categories then you must make a new category (eg, low, middle, high) or use another statistical procedure. Additionally, your expected values are required to be integers, not ratio. The number of observed and the number of expected must sum to the same total.
The chi-square test is a good example of such tests, and we will encounter other examples too. Another common goodness of fit is the coefficient of determination, which will be introduced in linear regression sections (see Chapter 17.7 – Regression model fit). Still other examples are the likelihood ratio test (LRT), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC), which are all used to assess fit of models to data. (See Graffelman and Weir [2018] for how to use AIC in the context of testing for Hardy Weinberg equilibrium.)
The likelihood ratio test is used to compare the goodness of fit of two hierarchically nested models to determine if a more complex model provides a significantly better fit to the data. It does this by forming a ratio of the likelihood of the data under the two models (the simpler “null” model and the more complex “alternative” model). A small ratio suggests the simpler model is a poor fit, while a value close to one indicates the added complexity is not statistically significant. AIC (and BIC) is a measure of relative fit — it balances goodness of fit and model complexity: A lower AIC suggests a better model by finding the optimal trade-off between fitting the data well and keeping the model simple. A model that is too complex will have a higher AIC than a simpler model with a nearly as good fit.
We use LRT, AIC and BIC when we talk about selecting best regression models (see Chapter 17.7 – Regression model fit). However, as we discuss the concept of comparing models, we need to distinguish between the concept of model choice — methods used to select a best model from competing options and estimating the “goodness of fit” of a single model.
How well does data fit the prediction?
Frequentist approach interprets the test as, how well does the data fit the null hypothesis,  ? When you compare data against a theoretical distribution (eg, Mendel’s hypothesis predicts the distribution of progeny phenotypes for a particular genetic system), you test the fit of the data against the model’s predictions (expectations). Recall that the Bayesian approach asks how well does the model fit the data?
? When you compare data against a theoretical distribution (eg, Mendel’s hypothesis predicts the distribution of progeny phenotypes for a particular genetic system), you test the fit of the data against the model’s predictions (expectations). Recall that the Bayesian approach asks how well does the model fit the data?
Table 2. A. 120 tosses of a coin, we count heads 70/120 tosses.
| Expected | Observed | |
| Heads | 60 | 70 |
| Tails | 60 | 50 |
| n | 120 | 120 |

Table 3. B. A possible Mendelian system of inheritance for a one gene, two allele system with complete dominance, observe the phenotypes.
| Expected | Observed | |
| Round | 75 | 84 |
| Wrinkled | 25 | 16 |
| n | 100 | 100 |

Table 4. C. A possible Mendelian system of inheritance for a one gene, two allele system with complete dominance, observe the phenotypes.
| Expected | Observed | |
| p2 | 70 | 45 |
| 2pq | 27 | 34 |
| q2 | 3 | 21 |
| n | 100 | 100 |

For completeness, instead of a goodness of fit test we can treat this problem as a test of independence, a contingency table problem. We’ll discuss contingency tables more in the next section, but or now, we can rearrange our table of observed genotypes for problem C, as a 2X2 table
Table 5. Problem C reported in 2X2 table format.
| Maternal a’ | Paternal a’ | |
| Maternal a | 45 | 17 |
| Paternal a | 17 | 21 |
The contingency table is calculated the same way as the GOF version, but the degrees of freedom are calculated differently: df = number of rows – 1 multiplied by the number of columns – 1.

Thus, for a 2X2 table the df are always equal to 1.
Note that the chi-square value itself says nothing about how any discrepancy between expectation and observed genotype frequencies come about. Therefore, one can rearrange the equation to make clear where deviance from equilibrium, D, occur for the heterozygote (het). We have

where D2 is equal to

φ coefficient
The chi-square test statistic and its inference tells you about the significance of the association, but not the strength or effect size of the association. Not surprisingly, Pearson (1904) came up with a statistic to quantify the strength of association between two binary variables, now called the φ (phi) coefficient. Like the Pearson product moment correlation, the φ (phi) coefficient takes values from -1 to +1.
Note 2: Pearson termed this statistic the mean square contingency coefficient. Yule (1912) termed it the phi coefficient. The correlation between two binary variables is also called the Mathews Correlation Coefficient or MCC (Mathews 1975), which is a common classification tool in machine learning.
The formula for the absolute value of φ coefficient is

Thus, for A, B, and C examples, φ coefficient was 0.167, 0.190, and 0.771. Thus, only weak associations in examples A and B, but strong association in C. We’ll provide a formula to directly calculate φ coefficient from the cells of the table in 9.2 – Chi-square contingency tables.
Carry out the test and interpret results
What was just calculated? The chi-square, , test statistic.
Just like t-tests, we now want to compare our test statistic against a critical value — calculate degrees of freedom (df = k – 1, k equals the numbers of categories), and set a rejection level, Type I error rate. We typically set the Type I error rate at 5%. A table of critical values for the chi-square test is available in Appendix Table Chi-square critical values.
Obtaining Probability Values for the goodness-of-fit test of the null hypothesis:
As you can see from the equation of the chi-square, a perfect fit between the observed and the expected would be a chi-square of zero. Thus, asking about statistical significance in the chi-square test is the same as asking if your test statistic is significantly greater than zero.
The chi-square distribution is used and the critical values depend on the degrees of freedom. Fortunately for and other statistical procedures we have Tables that will tell us what the probability is of obtaining our results when the null hypothesis is true (in the population).
Here is a portion of the chi-square critical values for probability that your chi-square test statistic is less than the critical value (Fig 1).
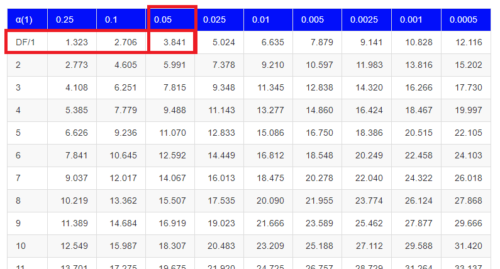
Figure 1. A portion of critical values of the chi-square at alpha 5% for degrees of freedom between 1 and 10. A more inclusive table is provided in the Appendix, Table of Chi-square critical values.
For the first example (A), we have df = 2 – 1 = 1 and we look up the critical value corresponding to the probability in which Type I = 5% are likely to be smaller iff (“if and only if”) the null hypothesis is true. That value is 3.841; our test statistic was 3.330, and therefore smaller than the critical value: so we do not reject the null hypothesis.
Interpolating p-values
How likely is our test statistic value of 3.333 and the null hypothesis was true? (Remember, “true” in this case is a shorthand for our data was sampled from a population in which the HW expectations hold). When I check the table of critical values of the chi-square test for the “exact” p-value, I find that our test statistic value falls between a p-value 0.10 and 0.05 (represented in the table below). We can interpolate
Note 3: Interpolation refers to any method used to estimate a new value from a set of known values. Thus, interpolated values fall between known values. Extrapolation on the other hand refers to methods to estimate new values by extending from a known sequence of values.
Table 6. Interpolated p-value for critical value not reported in chi-square table.
| statistic | p-value |
| 3.841 | 0.05 |
| 3.333 | x |
| 2.706 | 0.10 |
If we assume the change in probability between 2.706 and 3.841 for the chi-square distribution is linear (it’s not, but it’s close), then we can do so simple interpolation.
We set up what we know on the right hand side equal to what we don’t know on the left hand side of the equation,

and solve for x. Then, x is equal to 0.0724
R function pchisq() gives a value of p = 0.0679. Close, but not the same. Of course, you should go with the result from R over interpolation; we mention how to get the approximate p-value by interpolation for completeness, and, in some rare instances, you might need to make the calculation. Interpolating is also a skill used to provide estimates where the researcher needs to estimate (impute) a missing value.
Interpreting p-values
This is a pretty important topic, so much so that we devote an entire section to this very problem — see 8.2 – The controversy over proper hypothesis testing. If you skipped the chapter, but find yourself unsure how to interpret the p-value, then please go back to Ch 8.2. OK, that commercial message, what does it mean to “reject the chi-square null hypothesis?” These types of tests are called goodness of fit in the following sense — if your data agree with the theoretical distribution, then the difference between observed and expected should be very close to zero. If it is exactly zero, then you have a perfect fit. In our coin toss case, if we say that the ratio of heads:tails do not differ significantly from the 50:50 expectation, then we accept the null hypothesis.
You should try the other examples yourself! A hint, the degrees of freedom are one (1) for example B and two (2) for example C.
R code
Printed tables of the critical values from the chi-square distribution, or for any statistical test for that matter are fine, but with your statistical package R and Rcmdr, you have access to the critical value and the p-value of your test statistic simply by asking. Here’s how to get both.
First, let’s get the critical value.
Rcmdr: Distributions → Continuous distributions → Chi-squared distribution → Chi-squared quantiles (Fig 2).
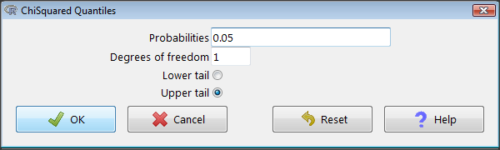
Figure 2. R Commander menu for Chi-squared quantiles.
I entered “0.05” for the probability because that’s my Type I error rate α. Enter “1” for Degrees of freedom, then click “upper tail” because we are interested in obtaining the critical value for α. Here’s R’s response when I clicked “OK.”
qchisq(c(0.05), df=1, lower.tail=FALSE) [1] 3.841459
Next, let’s get the exact P-value of our test statistic. We had three from three different tests:  for the coin-tossing example,
for the coin-tossing example,  for the pea example, and
for the pea example, and  for the Hardy-Weinberg example.
for the Hardy-Weinberg example.
Rcmdr: Distributions → Continuous distributions → Chi-squared distribution → Chi-squared probabilities… (Fig 3).
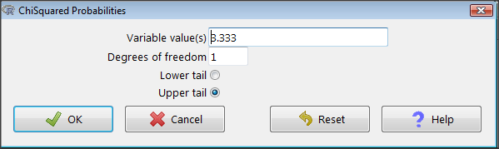
Figure 3. R Commander menu for Chi-squared probabilities.
I entered “3.333” because that is one of the test statistics I want to calculate for probability and “1” for Degrees of freedom because I had k – 1 = 1 df for this problem. Here’s R’s response when I clicked “OK.”
pchisq(c(3.333), df=1, lower.tail=FALSE) [1] 0.06790291
I repeated this exercise for I got  ; for I got
; for I got  .
.
Nice, right? Saves you from having to interpolate probability values from the chi-square table.
3. How to get the goodness of fit in Rcmdr.
R provides the goodness of fit (the command is chisq.text()), but Rcmdr thus far does not provide a menu option to link to the function. Instead, R Commander provides a menu for contingency tables, which also is a chi-square test, but is used where no theory is available to calculate the expected values (see Chapter 9.2). Thus, for the goodness of fit chi-square, we will need to bypass Rcmdr in favor of the script window. Honestly, other options are as quick or quicker: calculate by hand, use a different software (eg, Microsoft Excel), or many online sites provide JavaScript tools.
So how to get the goodness of fit chi-square while in R? Here’s one way. At the command line, type
chisq.test (c(O1, O2, ... On), p = c(E1, E2, ... En))
where O1, O2, … On are observed counts for category 1, category 2, up to category n, and E1, E2, … En are the expected proportions for each category. For example, consider our Heads/Tails example above (problem A).
In R, we write and submit
chisq.test(c(70,30),p=c(1/2,1/2))
R returns
Chi-squared test for given probabilities.
data: c(70, 30)
X-squared = 16, df = 1, p-value = 0.00006334
Easy enough. But not much detail — details are available with some additions to the R script. I’ll just link you to a nice website that shows how to add to the output so that it looks like the one below.
mike.chi <- chisq.test(c(70,30),p=c(1/2,1/2))
Let’s explore one at time the contents of the results from the chi square function.
names(mike.chi) #The names function
[1] "statistic" "parameter" "p.value" "method" "data.name" "observed"
[7] "expected" "residuals" "stdres"
Now, call each name in turn.
mike.chi$residuals [1] 2.828427 -2.828427 mike.chi$obs [1] 70 30 mike.chi$exp [1] 50 50
Note 4: “residuals” here simply refers to the difference between observed and expected values. Residuals are an important concept in regression, see Ch17.5
And finally, let’s get the summary output of our statistical test.
mike.chi Chi-squared test for given probabilities. data: c(70, 30) X-squared = 16, df = 1, p-value = 6.334e-05
GOF and spreadsheet apps
Easy enough with R, but it may even easier with other tools. I’ll show you how to do this with spreadsheet apps and with and online at graphpad.com.
Let’s take the pea example above. We had 16 wrinkled, 84 round. We expect 25% wrinkled, 75% round.
Now, with R, we would enter
chisq.test(c(16,80),p=c(1/4,3/4))
and the R output
Chi-squared test for given probabilities data: c(16, 80) X-squared = 3.5556, df = 1, p-value = 0.05935
Microsoft Excel and the other spreadsheet programs (Apple Numbers, Google Sheets, LibreOffice Calc) can calculate the goodness of fit directly; they return a P-value only. If the observed data are in cells A1 and A2, and the expected values are in B1 and B2, then use the procedure =CHITEST(A1:A2,B1:B2).
Table 7. A spreadsheet with formula visible.
| A | B | C | D | |
| 1 | 80 | 75 | ||
| 2 | 16 | 25 | =CHITEST(A1:A2,B1:B2) |
The P-value (but not the Chi-square test statistic) is returned. Here’s the output from Calc.
Table 8. Spreadsheet example from Table 7 with calculated P-value.
| A | B | C | D | |
| 1 | 80 | 75 | ||
| 2 | 16 | 25 | 0.058714340077662 |
You can get the critical value from MS Excel (=CHIINV(alpha, df), returns the critical value), and the exact probability for the test statistic =CHIDIST(x,df), where x is your test statistic. Putting it all together, a general spreadsheet template for goodness of fit calculations calculations of test statistic and p-value might look like
Table 9. Spreadsheet template with formula to calculate chi-square goodness of fit on two groups.
| A | B | C | D | E | |
| 1 | f1 | 0.75 | |||
| 2 | f2 | 0.25 | |||
| 3 | N | =SUM(A5,A6) |
|||
| 4 | Obs | Exp | Chi.value | Chi.sqr | |
| 5 | 80 | =B1* |
=((A5-B5)^2)/B5 |
=SUM(C5,C6) |
|
| 6 | 16 | =B2* |
=((A6-B6)^2)/B6 |
=CHIDIST(D5, COUNT(A5:A6-1) |
|
| 7 | |||||
| 8 |
 3
3Microsoft Excel can be improved by writing macros, or by including available add-in programs, such as the free PopTools, which is available for Microsoft Windows 32-bit operating systems only.
Another option is to take advantage of the internet — again, many folks have provided java or JavaScript-based statistical routines for educational purposes. Here’s an easy one to use www.graphpad.com.
In most cases, I find the chi-square goodness-of-fit is so simple to calculate by hand that the computer is redundant.
Questions
1. A variety of p-values were reported on this page with no attempt to reflect significant figures or numbers of digits (see Chapter 8.2). Provide proper significant figures and numbers of digits as if these p-values were reported in a science journal.
- 0.0724
- 0.0679
- 0.03766692
- 0.004955794
- 0.00006334
- 6.334e-05
- 0.05935
- 0.058714340077662
2. For a mini bag of M&M candies, you count 4 blue, 2 brown, 1 green, 3 orange, 4 red, and 2 yellow candies.
- What are the expected values for each color?
- Calculate using your favorite spreadsheet app (eg, Numbers, Excel, Google Sheets, LibreOffice Calc)
- Calculate using R (note R will reply with a warning message that the “Chi-squared approximation may be incorrect”; see 9.2 Yates continuity correction)
- Calculate using Quickcalcs at graphpad.com
- Construct a table and compare p-values obtained from the different applications
3. CYP1A2 enzyme involved with metabolism of caffeine. Folks with C at SNP rs762551 have higher enzyme activity than folks with A. Populations differ for the frequency of C. Using R or your favorite spreadsheet application, compare the following populations against global frequency of C is 33% (frequency of A is 67%).
- 286 persons from Northern Sweden: f(C) = 26%, f(A) = 73%
- 4532 Native Hawaiian persons: f(C) = 22%, f(A) = 78%
- 1260 Native American persons: f(C) = 30%, f(A) = 70%
- 8316 Native American persons: f(C) = 36%, f(A) = 64%
- Construct a table and compare p-values obtained for the four populations.
Quiz Chapter 9.1
Chi-square test: Goodness of fit
Chapter 9 contents
8.6 – Confidence limits for the estimate of population mean
Introduction
In Chapter 3.4 and Chapter 8.3, we introduced the concept of providing a confidence interval for estimates. We gave a calculation for an approximate confidence interval for proportions and for the Number Needed to Treat (Chapter 7.3). Even an approximate confidence interval gives the reader a range of possible values of a population parameter from a sample of observations.
In this chapter we review and expand how to calculate the confidence interval for a sample mean,  . Because is derived from a sample of observations, we use the t-distribution to calculate the confidence interval. Note that if the population was known (population standard deviation), then you would use normal distribution. This was the basis for our recommendation to adjust your very approximate estimate of a confidence interval for an estimate by replacing the “2” with “1.96” when you multiply the standard error of the estimate (SE) in the equation estimate
. Because is derived from a sample of observations, we use the t-distribution to calculate the confidence interval. Note that if the population was known (population standard deviation), then you would use normal distribution. This was the basis for our recommendation to adjust your very approximate estimate of a confidence interval for an estimate by replacing the “2” with “1.96” when you multiply the standard error of the estimate (SE) in the equation estimate  . As you can imagine, the approximation works for large sample size, but is less useful as sample size decreases.
. As you can imagine, the approximation works for large sample size, but is less useful as sample size decreases.
Consider ; it is a point estimate of  , the population mean (a parameter). But our estimate of is but one of an infinite number of possible estimates. The confidence interval, however, gives us a way to communicate how reliable our estimate is for the population parameter. A 95% confidence interval, for example, tells the reader that we are willing to say (95% confident) the true value of the parameter is between these two numbers (a lower limit and an upper limit). The point estimate (the sample mean) will of course be included between the two limits.
, the population mean (a parameter). But our estimate of is but one of an infinite number of possible estimates. The confidence interval, however, gives us a way to communicate how reliable our estimate is for the population parameter. A 95% confidence interval, for example, tells the reader that we are willing to say (95% confident) the true value of the parameter is between these two numbers (a lower limit and an upper limit). The point estimate (the sample mean) will of course be included between the two limits.
Instead of 95% confidence, we could calculate intervals for 99%. Since 99% is greater than 95%, we would communicate our certainty of our estimate.
Note 1: Again, the caveats about p-value extend to confidence intervals. See Chapter 8.2.
Question 1: For 99% confidence interval, the lower limit would be smaller than the lower limit for a 95% confidence interval.
- True

- False
When we set the Type I error rate,  (alpha) = 0.05 (5%), that means that 5% of all possible sample means from a population with mean, , will result in t values that are larger than
(alpha) = 0.05 (5%), that means that 5% of all possible sample means from a population with mean, , will result in t values that are larger than  OR smaller than
OR smaller than  .
.
Why the t-distribution?
We use the t-test because, technically, we have a limited sample size and the t-distribution is more accurate than the normal distribution for small samples. Note that as sample size increases, the t-distribution is not distinguishable from the normal distribution and we could use  (Fig 1).
(Fig 1).
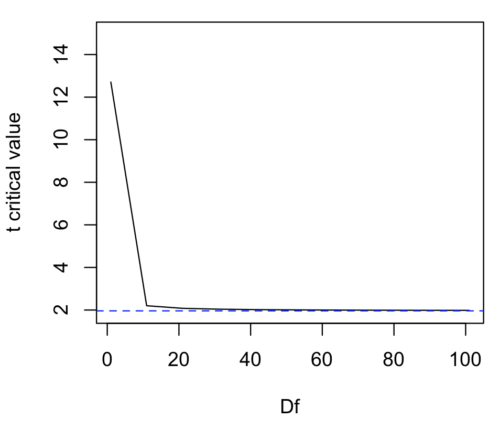
Figure 1. Critical values at Type I rate of 5% of t-distribution  . Blue dashed line is z = 1.96.
. Blue dashed line is z = 1.96.
Here’s the equation for calculating the confidence interval based on the t-distribution. These set the limits around our estimate of the sample mean. Together, they’re called the 95% confidence interval,  .
.
![\begin{align*} \left [ -t_{0.05\left ( 2 \right ),df} \leq \frac{\bar{X}-\mu}{s_{\bar{X}}}\leq +t_{0.05\left ( 2 \right ),df}\right ]=0.95 \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-3d905fd4c1df0b005fb5dbd6de5fda44_l3.png "Rendered by QuickLaTeX.com")
Here’s a simplified version of the same thing, but generalized to any Type I level…

This statistic allows us to say that we are 95% confident that the interval includes the true value for . For this confidence interval you need to identify the critical t value at 5%. Thus, you need to know the degrees of freedom for this problem, which is simply  , the sample size minus one.
, the sample size minus one.
It is straightforward to calculate these by hand, but…
Set the Type I error rate, calculate the degrees of freedom (df):
 samples for one sample test
samples for one sample test- pairs of samples for paired test
 samples for two independent sample test
samples for two independent sample test
and lookup the critical value from the t table (or from the t distribution in R). Of course, it is easier to use R.
In R, for the one tail critical value with seven degrees of freedom, type at the R prompt
qt(c(0.05), df=7, lower.tail=FALSE) [1] 1.894579
For the two-tail critical value
qt(c(0.025), df=7, lower.tail=FALSE) [1] 2.364624
Or, if you prefer to use R Commander, then follow the menu prompts to bring up the t quantiles function (Fig 2 and Fig 3).
Figure 2. Drop down menu to get t-distribution.
Note 2: Quantiles divide probability distribution into equal parts or intervals. Quartiles have four groups, deciles have ten groups, and percentiles have 100 groups.
Figure 3. Menu for t quantiles, with values entered for the two-tail example.
You should confirm that what R calculates agrees with the critical values tabulated in the Table of Critical values for the t distribution provided in the Appendix.
A worked example
Let’s revisit our lizard example from last time (see Chapter 8.5). Prior to conducting any inference test, we decide acceptable Type I error rates (cf justify alpha discussion in Ch8.1); For this example, we set Type I error rate to be 1% for a 99% confidence interval.
The Rcmdr output was
t.test(lizz$bm, alternative='two.sided', mu=5, conf.level=.99)
data: lizz$bm
t = -1.5079, df = 7, p-value = 0.1753
alternative hypothesis: true mean is not equal to 5
99 percent confidence interval:
1.984737 6.199263
sample estimates:
mean of x
4.092
Sort through the output and identify what you need to know.
Question 1: What was the sample mean?
- 5
- -1.5079
- 7
- 0.1753
- 1.984737
- 6.199263
- 4.092
Question 2: What was the most likely population mean?
- 5
- Answer
- -1.5079
- 7
- 0.1753
- 1.984737
- 6.199263
- 4.092
Question 3: This was a “one-tailed” test of the null hypothesis?
- True
- False
The output states “alternative hypothesis: true mean is not equal to 5” — so it was a two-tailed test.
Question 4: What was the lower limit of the confidence interval?
- 5
- -1.5079
- 7
- 0.1753
- 1.984737
- 6.199263
- 4.092
The 99% confidence interval,  , is
, is  , which means we are 99% certain that the population mean is between
, which means we are 99% certain that the population mean is between  (lower limit) and
(lower limit) and  (upper limit). In Chapter 8.5 we calculated the , is
(upper limit). In Chapter 8.5 we calculated the , is  .
.
Confidence intervals by nonparametric bootstrap sampling.
Bootstrapping is a general approach to estimation or statistical inference that utilizes random sampling with replacement (Kulesa et al. 2015). In classic frequentist approach, a sample is drawn at random from the population and assumptions about the population distribution are made in order to conduct statistical inference. By resampling with replacement from the sample many times, the bootstrap samples can be viewed as if we drew from the population many times without invoking a theoretical distribution. A clear advantage of the bootstrap is that it allows estimation of confidence intervals without assuming a particular theoretical distribution and thus avoids the burden of repeating the experiment. Which method to prefer? For cases where assumption of a particular distribution is unwarranted (e.g., what is the appropriate distribution when we compare medians among samples?), bootstrap may be preferred (and for small data sets, percentile bootstrap may be better). We cover bootstrap sampling of confidence intervals in Chapter 19.2 Bootstrap sampling.
Conclusions
The take home message is simple.
- All estimates should — must? — be accompanied by a Confidence Interval
- The more confident we wish to be, the wider the confidence interval will be
Note that the confidence interval concept combines DESCRIPTION (the population mean is between these limits) and INFERENCE (and we are 95% certain about the values of these limits). It is good statistical practice to include estimates of confidence intervals for any estimate you share with readers. Any statistic that can be estimated should be accompanied by a confidence interval and, as you can imagine, formulas are available to do just this. For example, earlier this semester we calculated NNT.
Questions
- To gain practice with calculations of confidence intervals, calculate the approximate confidence interval, the 95% and the 99% confidence intervals based on the t distribution, for each of the following.
-
- = 13,
 = 1.3,
= 1.3,  = 10
= 10 - = 13, = 1.3, = 30
- = 13, = 2.6, = 10
- = 13, = 2.6, = 30
Quiz Chapter 8.6
Confidence limits for the estimate of population mean
Chapter 8 contents
- Introduction
- The null and alternative hypotheses
- The controversy over proper hypothesis testing
- Sampling distribution and hypothesis testing
- Tails of a test
- One sample t-test
- Confidence limits for the estimate of population mean
- References and suggested readings
8.5 – One sample t-test
Introduction.
We’re now talking about the traditional, classical two group comparison involving continuous data types. Thus begins your introduction to parametric statistics. One sample tests involve questions like, how many — what proportion of — people would we expect are shorter or taller than two standard deviations from the mean? This type of question assumes a population and we use properties of the normal distribution and, hence, these are called parametric tests because the assumption is that the data has been sampled from a particular probability distribution.
However, when we start asking questions about a sample statistic (e.g., the sample mean), we cannot use the normal distribution directly, i.e., we cannot use Z and the normal table as we did before (Chapter 6.7). This is because we do not know the population standard deviation and therefore must use an estimate of the variation (s) to calculate the standard error of the mean.
With the introduction of the t-statistic, we’re now into full inferential statistics-mode. What we do have are estimates of these parameters. The t-test — aka Student’s t-test — was developed for the purpose of testing sample means when the true population parameters are not known.
Note 1: It’s called Student’s t-test after the pseudonym used by William Gosset.
The equation of the one sample t-test. Note the resemblance in form with the Z-score!

where  is the sample standard error of the sample mean (SEM).
is the sample standard error of the sample mean (SEM).
For example, weight change of mice given a hormone (leptin) or placebo. The  , but under the null hypothesis, the mean change is “really” zero (
, but under the null hypothesis, the mean change is “really” zero ( ). How unlikely is our value of 5 g?
). How unlikely is our value of 5 g?
Note 2: Did you catch how I snuck in “placebo” and mice? Do you think the concept of placebo is appropriate for research with mice, or should we simply refer to it as a control treatment? See Ch5.4 – Clinical trials for review.
Speaking of null hypotheses, can you say (or write) the null and alternative hypotheses in this example? How about in symbolic form?
We want to know if our sample mean could have been obtained by chance alone from a population where the true change in weight was zero.
and
and we take these values and plug them into our equation of the t-test
Then recall that Degrees of Freedom are DF = n – 1 so we have DF = 20 – 1 = 19 for the one sample t-test. And the Critical Value is found in the appropriate table of critical values for the t distribution (Fig 1)
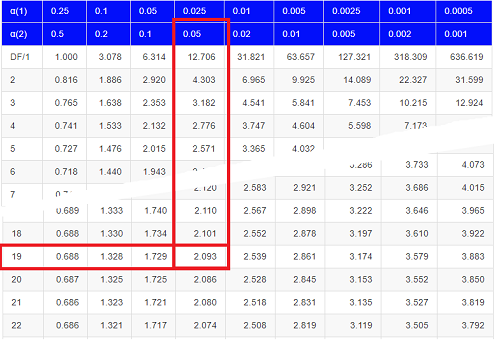
Figure 1. Table of a portion of the Critical values of the t distribution. Red selections highlight critical value for t-test at α = 5% and df = 19.
Note 3: See our table of critical values of t distribution.
Or, and better, use R
qt(c(0.025), df=19, lower.tail=FALSE)
where qt() is function call to find t-score of the pth percentile (cf 3.3 – Measures of dispersion) of the Student t distribution. For a two tailed test, we recall that 0.025 is lower tail and 0.025 is upper tail.
In this example we would be willing to reject the Null Hypothesis if there was a positive OR a negative change in weight.
This was an example of a “two-tailed test” which is “2-tail” or α(2) in Table of critical values of the t distribution.
Critical Value for α(2) = 0.05, df = 19, = 2.093
Do we accept or reject the Null Hypothesis?
A typical inference workflow.
Note the general form of how the statistical test is processed, a form which actually applies to any statistical inference test.
- Identify the type of data
- State the null hypothesis (2 tailed? 1 tailed?)
- Select the test statistic (t-test) and determine its properties
- Calculate the test statistic (the value of the result of the t-test)
- Find degrees of freedom
- For the DF, get the critical value
- Compare critical value to test statistic
- Do we accept or reject the null hypothesis?
And then we ask, given the results of the test of inference, What is the biological interpretation? Statistical significance is not necessarily evidence of biological importance. In addition to statistical significance, the magnitude of the difference — the effect size — is important as part of interpreting results from an experiment. Statistical significance is at least in part because of sample size — the large the sample size, the smaller the standard error of the mean, therefore even small differences may be statistically significant, yet biologically unimportant. Effect size is discussed in Ch9.1 – Chi-square test: Goodness of fit, Ch11.4 – Two sample effect size and Ch12.5 – Effect size for ANOVA.
R Code.
Let’s try a one-sample t-test. Consider the following data set: body mass of four geckos and four Anoles lizards (Dohm unpublished data).
For starters, let’s say that you have reason to believe that the true mean for all small lizards is 5 grams (g).
Geckos: 3.186, 2.427, 4.031, 1.995 Anoles: 5.515, 5.659, 6.739, 3.184
Get the data into R (Rcmdr)
By now you should be able to load this data in one of several ways. If you haven’t already entered the data, check out Part 07. Working with your own data in Mike’s Workbook for Biostatistics.
Once we have our data.frame, proceed to carry out the statistical test.
To get the one-sample t-test in Rcmdr, click on Statistics → Means → Single-sample t-test… Because there is only one numerical variable, Body.mass, that is the only one that shows up in the Variable (pick one) window (Fig 2).
Figure 2. Screenshot Rcmdr single-sample t-test menu.
Type in the value 5.0 in the Null hypothesis: m = u box.
Question 1: Quick! Can you write, in plain old English, the statistical null hypothesis???
Answer 1: For example: No difference between gecko and Anolis lizard mean body mass.
Click OK
The results go to the Output Window.
t.test(lizards$Body.mass, alternative='two.sided', mu=5.0, conf.level=.95) One Sample t-test data: lizards$Body.mass t = -1.5079, df = 7, p-value = 0.1753 alternative hypothesis: true mean is not equal to 5 95 percent confidence interval: 2.668108 5.515892 sample estimates: mean of x 4.092
end of R output
Let’s identify the parts of the R output from the one sample t-test. R reports the name of the test and identifies
- The
dataset$variableused (lizards$Body.mass). The data set was called “lizards” and the variable was “Body.mass”. R uses the dollar sign ($) to denote the dataset and variable within the data set. - The value of the t test statistic was (t = -1.5079). It is negative because the sample mean was less than the population mean — you should be able to verify this!
- The degrees of freedom, df = 7
- The p-value = 0.1753
- 95% confidence interval of the population mean; lower limit = 2.668108, upper limit = 5.515892
- The sample mean = 4.092
Take a step back and review.
Let’s make sure we “get” the logic of the hypothesis testing we have just completed.
Consider the one-sample t-test.
Step 1. Define HO and HA. The null hypothesis might be that a sample mean, , is equal to μ = 5.
The alternate is that the sample mean is not equal to 20.
Where did the value 5 come from? It could be a value from the literature (does the new sample differ from values obtained in another lab?). The point is that the value is known in advance, before the experiment is conducted, and that makes it a one-sample t-test.
One tailed hypothesis or two?
We introduced you to the idea of “tails of a test” (Ch08.4). As you should recall, a null/alternative hypothesis for a two-tailed test may be written as
Null hypothesis

versus the alternative hypothesis

where is the sample mean and is the population mean.
Alternatively, we can write one-tailed tests of null/alternative hypothesis

for the null hypothesis versus the alternative hypothesis

Question 2: Are all possible outcomes of the one-tailed test covered by these two hypotheses?
Answer 2: Yes
Question 3: What was the SEM for this problem?
Answer 3: It would be the sample standard deviation divided by the square root of the sample size.
Step 2. Decide how certain you wish to be (with what probability) that the sample mean is different from μ. As stated previously, in biology, we say that we are willing to be incorrect 5% of the time (Cowles and Davis 1982; Cohen 1994). This means we are likely to correctly reject the null hypothesis 100% – 5% = 95% of the time, which is the definition of statistical power. We do this by setting the Type I error to be 5% (alpha, α = 0.05). The Type I error is the chance that we will reject a null hypothesis, but the true condition in the population we sampled was actually “no difference.”
Step 3. Carry out the calculation of the test statistic. In other words, get the value of t from the equation above by hand, or, if using R (yes!) simply identify the test statistic value from the R output after conducting the one sample t test.
Step 4. Evaluate the result of the test. If the value of the test statistic is greater than the critical value for the test, then you conclude that the chance (the P-value) that the result could be from that population is not likely and you therefore reject the null hypothesis.
Question 4: What is the critical value for a one-sample t-test with df = 7?
Answer 4: From R, we get + 2.365 for the two-tailed test. R code was qt(c(.025), df=7, lower.tail=FALSE)
Hint; you need the table or better, use R
Rcmdr: Distributions → Continuous distributions → t distributions → t quantiles
You also need to know three additional things to answer this question.
- You need to know alpha (α), which we have said generally is set at 5%.
- You also need to know the degrees of freedom (DF) for the test. For a one sample t-test, DF = n – 1, where n is the sample size.
- You also must know whether your test is one or two-tailed.
- You then use the t-distribution (the tables of the t-distribution at the back of your book) to obtain the critical value. Note that if you use R, the actual p-value is returned.
Why learn the equations when I can just do this in R?
Rcmdr does this for you as soon as you click OK. Rcmdr returns the value of the test statistic and the p-value. R does not show you the critical value, but instead returns the probability that your test statistic is as large as it is AND the null hypothesis is true. From our one-sample t-test example, the Rcmdr output. The simple answer is that in order to understand the R output properly you need to know where each item of the output for a particual test comes from and how to interpret it. Thus, the best way is to have the equations available and to understand the algorithmic approach to statistical inference.
And, this is as good of time as any to show you how to skip the RCmdr GUI and go straight to R.
First, create your variables. At the R prompt enter the first variable
liz <- c("G","G","G","G","A","A","A","A")
and then create the second variable
bm <- c(3.186,2.427,4.031,1.995,5.515,5.659,6.739,3.184)
Next, create a data frame. Think of a data frame as another word for worksheet.
lizz <- data.frame(liz,bm)
Verify that entries are correct. At the R prompt type “lizz” wthout the quotes and you should see
lizz liz bm 1 G 3.186 2 G 2.427 3 G 4.031 4 G 1.995 5 A 5.515 6 A 5.659 7 A 6.739 8 A 3.184
End of R output
Carry out the t-test by typing at the R prompt the following
t.test(lizz$bm, alternative='two.sided', mu=5, conf.level=.95)
And, like the Rcmdr output we have for the one-sample t-test the following R output
One Sample t-test data: lizards$Body.mass t = -1.5079, df = 7, p-value = 0.1753 alternative hypothesis: true mean is not equal to 5 95 percent confidence interval: 2.668108 5.515892 sample estimates: mean of x 4.092
End of R output
which, as you probably guessed, is the same as what we got from RCmdr.
Question 5: From the R output of the one sample t-test, what was the value of the test statistic?
- -1.5079
- 7
- 0.1753
- 2.668108
- 5.515892
- 4.092
Answer 5: -1.5079
Note 4: BI311 students — On an exam you will be given portions of statistical tables and output from R. Thus you should be able to evaluate statistical inference questions by completing the missing information. For example, if I give you a test statistic value, whether the test is one- or two-tailed, degrees of freedom, and the Type I error rate alpha, you should know that you would need to find the critical value from the appropriate statistical table. On the other hand, if I give you R output, you should know that the p-value and whether it is less than the Type I error rate of alpha would be all that you need to answer the question.
Why fall back on statistical tables? Think of this as a basic skill. In statistics and for some statistical tests, Rcmdr and other software may not provide the information needed to decide that your test statistic is large, and a table in a statistics book is the best way to evaluate the test.
For now, double check Rcmdr by looking up the critical value from the t-table.
Check critical value against our test statistic
Df = 8 – 1 = 7
The test is two-tailed, therefore α(2)
α = 0.05 (note that two-tailed critical value is 2.365. T was equal to 1.51 (since t-distribution is symmetrical, we can ignore the negative sign), which is smaller than 2.365 and so we would agree with Rcmdr — we cannot reject the null hypothesis.
Question 6: From the R output of the one sample t-test, what was the P-value?
- -1.5079
- 7
- 0.1753
- 2.668108
- 5.515892
Answer 6: 0.1753
Question 7: We would reject the null hypothesis
- False
- True
Answer 7: False — p-value, 17.5%, is greater than Type I error of 5%.
Questions
Seven questions, with answers, were provided for you within the text in this chapter. Here’s one more, but without answers.
8. Here’s a small data set for you to try your hand at the one-sample t-test and Rcmdr. The dataset contains cell counts, five counts of the numbers of beads in a liquid with an automated cell counter (Scepter, Millipore USA). The true value is 200,000 beads per milliliter fluid; the manufacturer claims that the Scepter is accurate within 15%. Does the data conform to the expectations of the manufacturer? Write a hypothesis then test your hypothesis with the one-sample t-test. Here’s the data.
| scepter |
| 258900 |
| 230300 |
| 107700 |
| 152000 |
| 136400 |
Quiz Chapter 8.5
One sample t-test
Chapter 8 contents
8.4 – Tails of a test
Introduction
The basics of statistical inference is to establish the null and alternative hypotheses. Starting with the simplest cases, where there is one sample of observations and the comparison is against a population (theory) mean, how many possible comparisons can be made? The next simplest is the two-sample case, where we have two sets of observations and the comparison is against the two groups. Again, how many total comparisons may be made?
Let , “X bar”, equal the sample mean and , “mu”, represent the population mean. For sample means, designate groups by a subscript, 1 or 2. We then have Table 1.
Table 1. Possible hypothesis involving two groups
| Comparison | One-same | Two-sample |
| 1. |  |
 |
| 2. |  |
 |
| 3. |  |
 |
| 4. |  |
 |
| 5. |  |
 |
| 6. |  |
 |
Classical statistics classifies inference into null hypothesis, HO, vs. alternative hypotheses, HA, and specifies that we test null hypotheses based on the value of the estimated test statistic (see discussion about critical value and p-value, Chapter 8.2). From the list of six possible comparisons we can divide them into one-tailed and two-tailed differences (Table 1). By “tail” we are referring to the ends or tails of a distribution (Figure 1, Figure 2); where do our results fall on the distribution?
Two-tailed hypotheses: Comparison 1 and comparison 2 in the table above are two-tailed hypotheses. We don’t ask about the direction of any difference (less than or greater than).
Figure 1 shows the “two-tailed” distribution — if our results fall to the left ,  , or to the right
, or to the right  we reject the null hypothesis (blue regions in the curve). We divide the type I error into two equal halves.
we reject the null hypothesis (blue regions in the curve). We divide the type I error into two equal halves.
Note 1: It’s a nice trick to shade in regions of the curve. A package tigerstats includes the function pnormGC that simplifies this task.
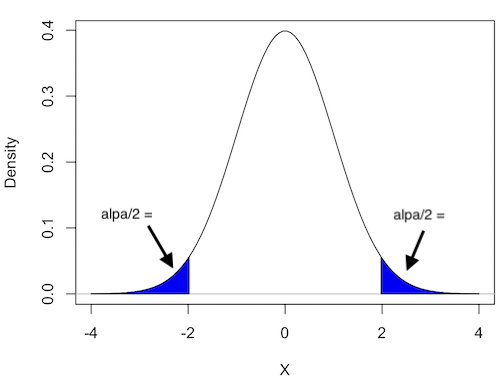
Figure 1. Two-tailed distribution.
RcmdrMisc::plotDistr(x = seq(-4, 4, length.out = 100),
p = dnorm(seq(-4, 4, length.out = 100)),
regions = list(c(-Inf, -1.96), c(1.96, Inf)),
xlab="X", ylab="Density",
col=c("blue"),
legend=FALSE)
Figure 2 shows the “one-tailed” distribution — if our alternative hypothesis was that the sample mean was less than the population mean, then our fall to the left,  , for the “lower tail” of the distribution. If, however, our alternative hypothesis was that the sample mean was greater than the population mean, then our region of interest falls to the right,
, for the “lower tail” of the distribution. If, however, our alternative hypothesis was that the sample mean was greater than the population mean, then our region of interest falls to the right,  . Again, we reject the null hypothesis (blue regions in the curve). Note for one-tailed hypothesis, all Type I error occurs in the one area, not both, so
. Again, we reject the null hypothesis (blue regions in the curve). Note for one-tailed hypothesis, all Type I error occurs in the one area, not both, so  (alpha) remains 0.05 over the entire rejection region (Fig 2).
(alpha) remains 0.05 over the entire rejection region (Fig 2).
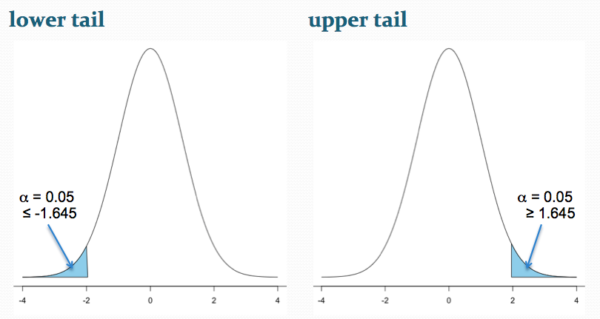
Figure 2. One-tailed distribution, lower tail (left) and upper tail (right).
library(tigerstats) pnormGC(1.645, region="above", mean=0, sd=1,graph=TRUE) pnormGC(-1.645, region="below", mean=0, sd=1,graph=TRUE)
One-tailed hypotheses: Comparison 3 through comparison 6 in the table are one-tailed hypotheses. The direction of the difference matters.
Note a simple trick to writing one-tailed hypotheses: first write the alternative hypothesis because the null hypothesis includes all of the other possible outcomes of the test.
Examples
Let’s consider some examples. We learn best by working through cases.
Chemotherapy as an approach to treat cancers owes its origins to the work of Dr Sidney Farber among others in the 1930s and ’40s (DeVita and Chu 2008; Mukherjee 2011). Following up on the observations of others that folic acid (vitamin B9) improved anemia, Dr Farber believed that folic acid might reverse the course of leukemia (Mukherjee 2011). In 1946 he recruited several children with acute lymphoblastic leukemia and injected them with folic acid. Instead of ameliorating their symptoms (e.g., white blood cell counts and percentage of abnormal immature white blood cells, called blast cells), treatments accelerated progression of the disease. That’s a scientific euphemism for the reality — the children died sooner in Dr. Faber’s trial than patients not enrolled in his study. He stopped the trials. Clearly, adding folic acid was not a treatment against this leukemia.
Question 1. Do you think these experiments are one sample or two sample? Hint: Is there mention of a control group?
Answer: There’s no mention of a control group, but instead, Dr. Faber would have had plenty of information about the progression of this disease in children. This was a one sample test.
Question 2. What would be a reasonable interpretation of Dr Faber’s alternative hypothesis with respect to percentage of blast cells in patients given folic acid treatment? Your options are
- Folic acid supplementation has an effect on blast counts.
- Folic acid supplementation reduces blast counts.
- Folic acid supplementation increases blast counts.
- Folic acid supplementation has no effect on blast counts.
Answer: At the start of the trials, it is pretty clear that the alternative hypothesis was intended to be a one-tailed test (option 2). Dr. Faber’s alternative hypothesis clearly was that he believed that addition of folic acid would reduce blast cell counts. However, that they stopped the trials shows that they recognized that the converse had occurred, that blast counts increased; this means that, from a statistician’s point of view, Dr Faber’s team was testing a two-sided hypothesis (option 1).
Another example.
Dr Farber reasoned that if folic acid accelerated leukemia progression, perhaps anti-folic compounds might inhibit leukemia progression. Dr Farber’s team recruited patients with acute lymphoblastic leukemia and injected them with a folic acid agonist called aminopterin. Again, he predicted that blast counts would reduce following administration of the chemical. This time, and for the first time in recorded medicine, blast counts of many patients drastically reduced to normal levels and the patients experienced remissions. The remissions were not long lasting and all patients eventually succumbed to leukemia. Nevertheless, these were landmark findings — for the first time a chemical treatment was shown to significantly reduce blast cell counts, even leading to remission, if however brief (Mukherjee 2011).
Try Question 3 and Question 4 yourself.
Question 3. Do you think these experiments are one sample or two sample? Hint: Is there mention of a control group?
Question 4. What would be a reasonable interpretation of Dr Faber’s alternative hypothesis with respect to percentage of blast cells in patients given aminopterin treatment? Your options are
- Aminopterin supplementation has an effect on blast counts.
- Aminopterin supplementation reduces blast counts.
- Aminopterin supplementation increases blast counts.
- Aminopterin supplementation has no effect on blast counts.
Pros and Cons to One-sided testing
Here’s something to consider: why not restrict yourself to one-tailed hypothesis?
Here’s the pro-argument for one-tailed tests. Strictly speaking you gain statistical power to test the null hypothesis. For example, look up the t-test distribution for degrees of freedom equal to 20 and compare  (one tail) vs.
(one tail) vs.  (two-tail). You will find that for the one-tailed test, the critical value of the t-distribution with 20 df is 1.725, whereas for the two-tailed test, the critical value of the t-distribution with the same numbers of df is 2.086. Thus, the difference between means can be much smaller in the one-tailed test and prove to be “statistically significant.” Put simply, with the same data, we will reject the Null Hypothesis more often with one-tailed tests.
(two-tail). You will find that for the one-tailed test, the critical value of the t-distribution with 20 df is 1.725, whereas for the two-tailed test, the critical value of the t-distribution with the same numbers of df is 2.086. Thus, the difference between means can be much smaller in the one-tailed test and prove to be “statistically significant.” Put simply, with the same data, we will reject the Null Hypothesis more often with one-tailed tests.
Or better yet, if during exploratory data analysis you see a clear difference between the groups and it is in the direction your scientific intuition suggests it should be, shouldn’t you switch to a one-tailed hypothesis? That’s a hard no. You would be “guilty” of p-hacking — the inappropriate manipulation of data analysis to get a more favored, statistically significant result.
The con-argument. If you use a one-tailed test you MUST CLEARLY justify its use and be aware that a deviation in the opposite direction MUST be ignored! More specifically, you interpret a one-tailed result in the opposite direction as acceptance of the null — you cannot, after the fact, change your mind and start speaking about “statistically significant differences” if you had specified a one-tailed hypothesis and the results showed differences in the opposite direction.
Note 2: Recall also that, by itself, statistical significance judged by the p-value against a specified cut-off critical value is not enough to say there is evidence for or against the hypothesis. For that we need to consider effect size, see Power analysis in Chapter 11.
Questions
- For a Type I error rate of 5% and the following degrees of freedom, compare the critical values for one tail test and a two tailed test of the null hypothesis.
- 5 df
- 10 df
- 15 df
- 20 df
- 25 df
- 30 df
- Using your findings from Additional Question 1, make a scatterplot with degrees of freedom on the horizontal axis and critical values on the vertical axis. What trend do you see for the difference between one and two tailed tests as degrees of freedom increase?
- A clinical nutrition researcher wishes to test the hypothesis that a vegan diet lowers total serum cholesterol levels compared to an omnivorous diet. What kind of hypothesis should he use, one-tailed or two-tailed? Justify your choice.
- Spironolactone, introduced in 1953, is used to block aldosterone in hypertensive patients. A newer drug eplerenone, approved by the FDA in 2002, is reported to have the same benefits as spironolactone (reduced mortality, fewer hospitalization events), but with fewer side effects compared with spironolactone. Does this sentence suggest a one-tailed test or a two-tailed test?
- Write out the appropriate null and alternative hypothesis statements for the spironolactone and eplerenone scenario.
- You open up a bag of Original Skittles and count the number of green, orange, purple, red, and yellow candies in the bag. What kind of hypothesis should be used, one-tailed or two-tailed? Justify your choice.
- Verify the probability values from the table of standard normal distribution for Z equal to -1.96, -1.645, 1.645, and 1.96.
Quiz Chapter 8.4
Tails of a test
Chapter 8 contents
8.3 – Sampling distribution and hypothesis testing
Introduction
Understanding the relationship between sampling distributions, probability distributions, and hypothesis testing is the crucial concept in the NHST — Null Hypothesis Significance Testing — approach to inferential statistics. is crucial, and many introductory text books are excellent here. I will add some here to their discussion, perhaps with a different approach, but the important points to take from the lecture and text are as follows.
Our motivation in conducting research often culminates in the ability (or inability) to make claims like:
- “Total cholesterol greater than 185 mg/dl increases risk of coronary artery disease.”
- “Average height of US men aged 20 is 70 inches (1.78 m).”
- “Species of amphibians are disappearing at unprecedented rates.”
Lurking beneath these statements of “fact” for populations (just what IS the population for #1, for #2, and for #3?) is the understanding that not ALL members of the population were recorded.
How do we go from our sample to the population we are interested in? Put another way — How good is our sample? We’ve talked about how “biostatistics” can be generalized as sets of procedures you use to make inferences about what’s happening in populations. These procedures include:
- Have an interesting question
- Experimental design (Observational study? Experimental study?)
- Sampling from populations (Random? Haphazard?)
- Hypotheses: HO and HA
- Estimate parameters (characterize the population)
- Tests of hypotheses (inferences)
We have control of each of these — we choose what to study, we design experiments to test our hypotheses…We have already introduced these topics (Chapters 6 – 8).
We also obtain estimates of parameters, and inferential statistics applies to how we report our descriptive statistics (Chapter 3). Estimates of parameters like the sample mean and sample standard deviation can be assessed for accuracy and precision (e.g., confidence intervals).
Sampling distribution
Imagine drawing a sample of 30 from a population, calculating the sample mean for a variable (e.g., systolic blood pressure), then calculating a second sample mean after drawing a new sample of 30 from the same population. Repeat, accumulating one estimate of the mean, over and over again. What will be the shape of this distribution of sample means? The Central Limit Theorem states that the shape will be a normal distribution, regardless of whether or not the population distribution was normal, as long as the sample size is large (i.e., Law of Large Numbers). We alluded to this concept when we introduced discrete and continuous distributions (Chapter 6).
It’s this result from theoretical statistics that allows us to calculate the probability of an event from a sample without actually carrying out repeated sampling or measuring the entire population.
A worked example
To demonstrate the CLT we want R to help us generate many samples from a particular distribution and calculate the same statistic on each sample. We could make a for loop, but the replicate() function provides a simpler framework. We’ll sample from the chi-square distribution. You should extend this example to other distributions on your own, see Question 5 below.
Note 1: This example is much simpler to enter and run code in the script window, adjusting code directly as needed. If you wish to try to run this through Rcmdr, you’ll need to take a number of steps, and likely need to adjust the code and rerun anyway. Some of the steps in would be Rcmdr: Distributions → Continuous distributions → Chi-squared distribution → Sample from chi-square distribution…, then running Numerical summaries and saving the output to an object (e.g., out), extracting the values from the object (e.g., out$Table, confirm by running command str(out)— str() is an R utility to display the structure of an object), then testing the object for normality Rcmdr: Statistics → Test of normality, select Shapiro-Wilk, etc.. In other words, sometimes a GUI is a good idea, but in many cases, work with the script!
Generate x replicate samples (e.g., x = 10, 100, 1000, one million) of 30 each from chi-square distribution with one degree of freedom, test the distribution against null hypothesis (assume normal distributed, e.g., Shapiro-Wilk test, see Chapter 13.3), then make a histogram (Chapter 4.2), like Figure 1 or Figure 2.
x.10 <- replicate(10, { my.mean <- rchisq(30, 1) mean(my.mean) }) normalityTest(~x.10, test="shapiro.test") hist(x.10, col="orange")
Result from R
Shapiro-Wilk normality test
data: x.10
W = 0.87016, p-value = 0.1004
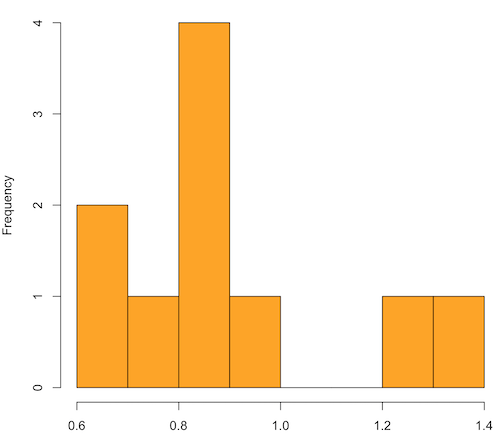
Figure 1. means of ten replicate samples drawn at random from chi-square distribution, df = 1.
Modify the code to draw 100 samples, we get Fig 2.
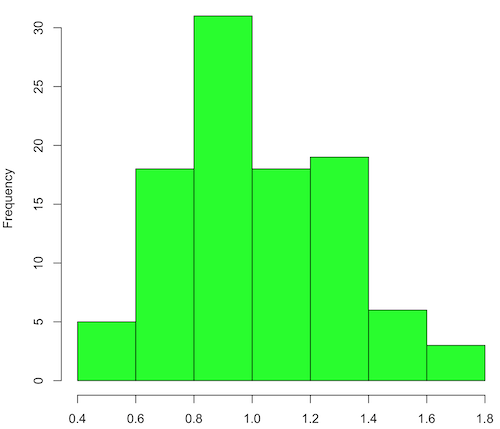
Figure 2. means of 100 replicate samples drawn at random from chi-square distribution, df = 1. Results from Shapiro-Wilks test: W = 0.97426, p-value = 0.04721.
And finally, modify the code to draw one million samples, we get Figure 3.
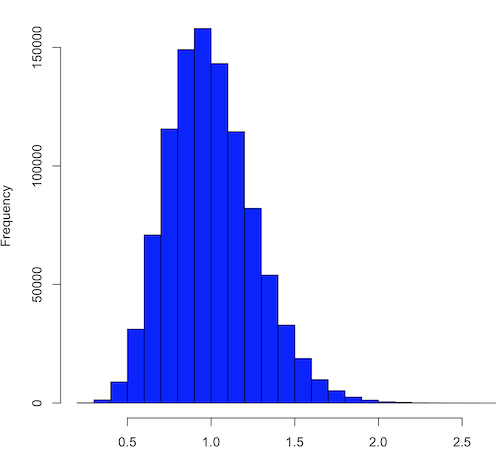
Figure 3. means of one million replicate samples drawn at random from chi-square distribution, df = 1. Normality test will fail to run, sample size of 5000 limit.
How to apply sampling distribution to hypothesis testing
First, a reminder of some definitions.
Estimate = we will always (almost) concern ourselves with how good our sample mean (such values are called estimates) is relative to the population mean, the thing we really want, but can only hope to get an estimate of.
Accuracy = how close to the true value is our measure?
Precision = how repeatable is our measure?
How can we tell if we have a good estimate? We want an estimate with an evaluation for accuracy and for precision. The sampling error provides an assessment of precision, whereas the confidence interval provides a statement of accuracy. We need an estimate of the sampling error for the statistic,
Sample standard error of the mean
We introduced sample error of the mean in section 3.4 of Chapter 3. Everything we measure can have a corresponding statement about how accurate (sampling error) is our estimate! First, we begin by asking, “how accurate is the mean that we estimate from a sample of a population?” How do we answer this? We could prove it in the mathematical sense of proof (and people have and do) OR we can use the computer to help. We’ll try this approach in a minute.
What we will show relates to the standard error of the population mean (SEM) or
![\[s_{\bar{X}}\]](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-80914fc397fd287f7f198558ca241048_l3.png "Rendered by QuickLaTeX.com")
, whose equation is shown below.

or equivalently, from the standard deviation we have

Note that the SEM takes the variance and divides through by the sample size. In general, then, the larger the sample size, the smaller the “error” around the mean. As we work through the different statistical tests, t-tests, analysis of variance, and related, you will notice that the test statistic is calculated as a ratio between a difference or comparison divided by some form of an error measurement. This is to remind you that “everything is variable.”
A note on standard deviation (SD) and standard error of the mean (SEM): SD estimates the variability of a sample of Xi‘s whereas SEM estimates the variability of a sample of means.
Let’s return to our thought problem and see how to demonstrate a solution. First, what is the population? Second, can we get the true population mean?
One way, a direct (but impossible?) approach would be to measure it — get all of the individuals in a population and measure them, then calculate the population mean. Then, we could compare our original sample mean against the true mean and see how close it was. This can be accomplished in some limited cases. For example, the USA conducts a census of her population every ten years, a procedure which costs billions of dollars. We can then compare samples from the different states or counties to the USA mean. And these statistics are indeed available via the census.gov website. But even the census uses sampling — individuals are randomly selected to answer more questions and from this sample trends in the population are inferred.
So, sampling from populations is the way to go for most questions we will encounter. The procedures we will use to show how a sample mean relates to the population mean are general and may be used to show how any estimate of a variable (sample mean and sample standard deviation, etc.), relates to properties of a parameter. We’ll get to the other issues, but for now, think about sample size.
Sampling from populations is necessary and inevitable, and, to a certain extent, under your control. But how many individuals do we need? The quick answer is for me to direct your attention to the equation for the SEM. Can you see in that ratio the secret to obtaining more precise estimates? There are many ways to approach this question, but let’s use the tools from last time, those based on properties of a normal distribution.
If we can view the sampling as having come from a population at least approximately normally distributed for our variable, then we can now examine empirically the effect of different sample sizes on the estimate of the mean.
A hint: variability is important!
From one population we obtain two samples, A and B. Sample sizes are

Assume for now that we know the true mean (μ) and standard deviation (σ) for the population. Note. This is one of the points of why we use computer simulation so much to teach statistics — it allows us to specify what the truth is, then see how our statistical tools work or how our assumptions affect our statistically based conclusions.

Confidence intervals
Reliability is another word for precision. We define a confidence interval as a statistic to report the reliability of our estimated statistic. We introduced confidence interval in Chapter 3.4. At least in principle, confidence intervals can be calculated for all statistics (mean, variance, etc.,) and for all data types. Confidence intervals define a lower limit, L, and an upper limit, U, and that you are making a statement that you are “95% certain that the true value (parameter value) is between these two limits.
We previously reported how to calculate an approximate confidence intervals for proportions and for NNT; simply multiple standard error estimate by 2. Here we introduce an improved approximate calculation of the 95% confidence interval for the sample mean

where Z is something you would look up from the table of the normal distribution. For a 95% confidence interval, 100% – 95% = 5% and divide 5% by two: the lower limit corresponds to 2.5% and the upper limit corresponds to 2.5% on our normal distribution. We look up the table and we find that Z for 0.025 is 1.96 and that is the value we would plug into our equation above. For large sample sizes, you can get a pretty decent estimate of the confidence interval by replacing 1.96 with “2.”
Questions
1. What is the probability of having a sample mean greater than 50 (mean > 50) for a sample of n = 9 ?
We’ll use a slight modification of the Z-score equation we introduced in Chapter 6.6 — the modification here is that previously we referred to the distribution of Xi‘s and how likely a particular observation would be. Instead, we can use the Z score with the standard normal distribution (aka Z-distribution), approach to solving how likely an estimated sample mean is given the population parameters μ and σ. Recall the Z score

We have everything we need except the SEM, which we can calculate by dividing the standard deviation by squared root of sample size.
For
![\[\bar{X} = 50\]](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-e1a072ca9f8d1aa2fff8a8f5a829a9d5_l3.png "Rendered by QuickLaTeX.com")
, σ = 12.0 (given above), and μ = 47, n = 9, plug in the values:

Therefore, after applying the equation for Z score,  . This corresponds to how far away from the standard mean of zero.
. This corresponds to how far away from the standard mean of zero.
Look up from the table of normal distribution. The answer is  , which corresponds to that
, which corresponds to that  is EQUAL to or GREATER than 0.75, which is what we wanted. Translated, this implies that, given the level of variability in the sample, 22.66% of your sample means would be greater than 50! We write:
is EQUAL to or GREATER than 0.75, which is what we wanted. Translated, this implies that, given the level of variability in the sample, 22.66% of your sample means would be greater than 50! We write:  .
.
Some care needs to be taken when reading these tables — make sure you understand how the direction (less than, greater than) away from the mean is tabulated.
2. Instead of greater, how would you get the probability less than 50?
Total area under the curve is 1 (100%), so subtract  .
.
I recommend that you do these by hand first, then check your answers. You’ll need to be able to do this for exams.
Here’s how to use Rcmdr to do these kind of problems.
Rcmdr: Distributions → Continuous distributions → Normal distribution → Normal probabilities …
Figure 5. Screenshot Rcmdr menu to get normal probability.
Here’s the answer from Rcmdr
pnorm(c(50), mean=47, sd=12, lower.tail=TRUE) [1] 0.5987063
3. Now, try a larger sample size. For  , what is the probability of having a sample mean greater than 50 (
, what is the probability of having a sample mean greater than 50 ( )?
)?
, μ = 47, σ = 12, n = 50 and
![\[SEM = \frac{12.0}{\sqrt{50}} = 1.697\]](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-62a98310dcd72f847a8190d0d36a8e66_l3.png "Rendered by QuickLaTeX.com")
Therefore, after applying the equation for Z score,  . Look up (Normal table, subtract answer from 1) and we get
. Look up (Normal table, subtract answer from 1) and we get  .
.
Or 3.84% of your sample means would be greater than 50! We write:  .
.
Said another way: If you have a sample size of 50 () and you obtain a mean greater than 50 then there is only a 3.84% chance that the TRUE MEAN IS 47.
4. What happens if the variability is smaller? Chance σ from 12 to 6 then repeat questions 1 and 4.
5. Repeat the demonstration of Central Limit Theorem and Law of Large Numbers for discrete distributions
- binomial distribution. Replace
rchisq()withrbinom(n, size, prob)in thereplicate()function example. See Chapter 6.5 - poisson distribution. Replace
rchisq()withrpois(n, lambda)in thereplicate()function example. See Chapter 6.5
Quiz Chapter 8.3
Sampling distribution and hypothesis testing
Chapter 8 contents
- Introduction
- The null and alternative hypotheses
- The controversy over proper hypothesis testing
- Sampling distribution and hypothesis testing
- Tails of a test
- One sample t-test
- Confidence limits for the estimate of population mean
- References and suggested readings
8.2 – The controversy over proper hypothesis testing
Introduction
Over the next several chapters we will introduce and develop an approach to statistical inference, which has been given the title “Null Hypothesis Significance Testing” or NHST.
In outline, NHST proceeds with
- statements of two hypotheses, a null hypothesis, HO, and an alternative hypothesis, HA
- calculate a test statistic comparison of the null hypothesis (assuming some characteristic of data).
- The value of the test statistic is to be compared to a critical value for the test, identified for the assumed probability distribution at associated degrees of freedom for the statistical function, and assigned Type I error rate.
We will expand on these statements later in this chapter, so stay with me here. Basically, the null hypothesis is often a statement like the responses of subjects from the treatment and control groups are the same, e.g., no treatment effect. Note that the alternative hypothesis, e.g., hypertensive patients receiving hydalazine for six weeks have lower systolic blood pressure than patients receiving a placebo (Campbell et al 2011), would be the scientific hypothesis we are most interested in. But in the Frequentist NHST approach we test the null hypothesis, not the alternative hypothesis. This framework over proper hypothesis testing is the basis of the Bayesian vs Frequentist controversy.
Consider the independent sample t-test (see Chapter 8.5 and 8.6), our first example of a parametric test.

After plugging in the sample means and the standard error for the difference between the means, we calculate t, the test statistic of the t-test. The critical value is treated as a cut-off value in the NHST approach. We have to set our Type I error rate before we start the experiment, and we have available the degrees of freedom for the test, which follows from the sample size. With these in hand, the critical value is found by looking in the t-table of probabilities (or better, use R).
For example, what is the critical value of t-test with 10 degrees of freedom and Type I error of 5%?
In Rcmdr, choose Distributions → Continuous distributions → t distribution → t quantiles… (Fig 1).
Figure 1. Screenshot t-quantiles Rcmdr menu.
Note we want Type I equal to 5%. Since there are two tails for our test, we divide 5% by two and enter 0.025 and select the Upper tail.
R output
> qt(c(.025), df=10, lower.tail=FALSE) [1] 2.228139
which is the same thing we would get if we look up on the t-distribution table (Fig 2).
Figure 2. Screenshot of portion of t-table with highlighted (red) critical value for 10 degrees of freedom.
If the test statistic is greater than the critical value, then the conclusion is that the null hypothesis is to be provisionally rejected. We would like to conclude that the alternative hypothesis should favored as best description of the results. However, we cannot — the p-value simply tells us how likely our results would be obtained and if the null hypothesis was true. Confusingly, however, you cannot interpret the p-value as telling you the probability (how likely) that the null hypothesis is true. If however the test statistic is less than the critical value, then the conclusion is that the null hypothesis is to be provisionally accepted.
The test statistic can be assigned a probability or p-value. This p-value is judged to be large or small relative to an a priori error probability level cut off called the Type I error rate. Thus, NHST as presented in this way may be thought of as a decision path — if the test statistic is greater than the critical value, which will necessarily mean that the p value is less than the Type I error rate, then we make one type of conclusion (reject HO). In contrast, if the test statistic is less than the critical value, which will mean that the p-value associated with the test statistic will be greater than the Type I error rate, then we conclude something else about the null hypothesis. The various terms used in this description of NHST were defined in Chapter 8.3.
Sounds confusing, but, you say, OK, what exactly is the controversy? The controversy has to do whether the probability or p-value can be interpreted as evidence for a hypothesis. In one sense, the smaller the p-value, the stronger the case to reject the null hypothesis, right? However, just because the p-value is small — the event is rare — how much evidence do we have that the null hypothesis is true? Not necessarily, and so we can only conclude that the p-value is one part of what we may need for evidence for or against a hypothesis (hint: part of the solution is to consider effect size — introduced in Chapter 9.2 — and the statistical power of the test, see Ch 11). What follows was covered by Goodman (1988) and others. Here’s the problem. Consider tossing a fair coin ten times, with the resulting trial yielding nine out of ten heads (e.g., a value of one, with tails equal to zero).
R code
set.seed(938291156) rbinom(10,1,0.5) [1] 1 1 1 1 1 1 0 1 1 1
Note 1: To get this result I repeated rbinom() a few times until I saw this rare result. I then used the command get_seed() from mlr3misc package to retrieve current seed of R’s random number generator. Initialize the random seed with the command set.seed().
While rare (binomial probability 0.0098), do we take this as evidence that the coin is not fair? By itself, the p-value provides no information about the alternative hypothesis. More about p-value follows below in sections What’s wrong with the p-value from NHST? and The real meaning and interpretation of P-values.
Statisticians have been aware of limitations of the NHST approach for years (see editorial by Wasserstein et al 2019), but only now is the message getting attention of researchers in the biosciences and other fields. In fact, the New York Times recently had a nice piece by F.D. Flam (“The Odds, Continually Updated,” 29 Sep 2014) on the controversy and the Bayesian alternative. Like most controversies there are strong voices on either side, and it can be difficult as an outsider to know which position to side with (Fig 3).

Figure 3. “Frequentists vs. Bayesians,” https://xkcd.com/1132/.
The short answer is — as you go forward do realize that there is a limitation to the frequentist approach and to be on the correct side of the controversy, you need to understand what you can conclude from statistical results. NHST is by far the most commonly used approached in biosciences (e.g., out of 49 research articles I checked from four randomly selected issues of 2015 PLoS Biology, 43 used NHST, 2 used a likelihood approach, none used Bayesian statistics). The NHST is also the overwhelming manner in which we teach introductory statistics courses (e.g., checking out the various MOOC courses at www.coursera.org, all of the courses related to Basic Statistics or Inferential Statistics are taught primarily from the NHST perspective). However, right from the start I want to emphasize the limits of the NHST approach.
If the purpose of science is to increase knowledge, then the NHST approach by itself is an inadequate framework at best, and in the eyes of some, worthless! Now, I think this latter sentiment is way over the top, but there is a need for us to stop before we begin, in effect, to set the ground rules for what can be interpreted from the NHST approach. The critics of NHST have a very important point, and that needs to be emphasized, but we will also defend use and teaching of this approach so that you are not left with the feeling that somehow this is a waste of time or that you are being cheated from learning the latest knowledge on the subject of statistical inference. The controversy hinges on what probability means.
P-values, statistical power, and replicability of research findings
Science, as a way of knowing how the world works, is the only approach that humans have developed that has been empirically demonstrated to work. Note how I narrowed what science is good for — if we are asking questions about the material world, then science should be your toolkit. Some (e.g., Platt 1964), may further argue that there are disciplines in science that have been more successful (e.g., molecular biology) than others (e.g., evolutionary psychology, cf discussion in Ryle 2006) at advancing our knowledge about the material world. However, to the extent research findings are based solely on statistical results there is reason to believe that many studies in fact have not recovered truth (Ioannidis 2005).
In a review of genomics, it was reported that findings of gene expression differences by many microarray studies were not reproducible (Allison et al 2006). The consensus is that confidence in the findings should hold only for the most abundant gene transcripts of many microarray gene expression profiling studies, a conclusion that undercuts the perceived power of the technology to discover new causes of disease and the basis for individual differences for complex phenotypes. Note that when we write about failure of research reproducibility we are not including cases of alleged fraud (Carlson 2012 on Duke University oncogenomics case), we are instead highlighting that these kinds of studies often lack statistical power; hence, when repeated, the experiments yield different results.
Frequentist and Bayesian Probabilities
Turns out there is a lot of philosophical problems around the idea of “probability,” and three schools of thought. In the Fisherian approach to testing, the researcher devises a null hypothesis, HO, collects the data, then computes a probability (p-value) of the result or outcome of the experiment. If the p-value is small, then this is inferred as little evidence in support of the null hypothesis.
In the Frequentists’ approach, the one we are calling NHST, the researcher devises two hypotheses, the null hypothesis, HO, and an alternative hypothesis, HA. The results are collected from the experiment and, prior to testing, a Type I error rate (α, chance) is defined. The Type I error rate is set to some probability and refers to the chance of rejecting the null hypothesis purely due to random chance. The Frequentist then computes a p-value of result of the experiment and applies a decision criterion: If P-value greater than Type I error rate, then provisionally accept null hypothesis. In both the Fisherian and Frequentist approaches, the probability, again defined at the relative frequency of an event over time, is viewed as a physical, objective and well-defined set of values.
Bayesian approach: based on Bayes conditional probability, one identifies the prior (subjective) probability of an hypothesis, then, adjusts the prior probability (down or up) as new results come in. The adjusted probability is known as posterior probability and it is equal to the likelihood function for the problem. The posterior probability is related to the prior probability and this function can be summarized by the Bayes factor as evidence the evidence against the null hypothesis. And that’s what we want, a metric of our evidence for or against the null hypothesis.
Note 2: A probability distribution function (PDF) is a function of the sample data and returns how likely that particular point will occur in the sample. The distribution is given. The likelihood function approaches this from a different direction. The likelihood function takes the data set as a given and represents how likely are the different parameters for your distribution.
We can calibrate the Bayesian probability to the frequentist p-value (Selke et al 2001; Goodman 2008; Held 2010; Greenland and Poole 2012). Methods to achieve this calibration vary, but the Fagan nomogram Held (2010) proposed is a good tool for us as we go forward. We can calculate our NHST p-value, but then convert the p-value to a Bayes factor by looking at the nomogram. I mention this here not as part of your to do list, but rather as a way past the controversy: the NHST p-value can be interpreted as a Bayesian conditional probability, but they do not test the same hypothesis.
Likelihood
Before we move on there is one more concept to introduce, that of likelihood. We describe a model (an equation) we believe can generate the data we observe. By constructing different models with different parameters (hypotheses), you generate a statistic that yields a likelihood value. If the model fits the data, then the likelihood function has a small value. The basic idea then is to compare related, but different models to see which fits the data better. We will use this approach when comparing linear models when we introduce multiple regression models in Chapter 18.
What’s wrong with the p-value from NHST?
Well, really nothing is “wrong” with the p-value.
Where we tend to get into trouble with the p-value concept is when we try and interpret it. See below, Why is this important to me as a beginning student? The p-value is not evidence for a position, it is a statement about error rates. The p-value from NHST can be viewed as the culmination of a process that is intended to minimize the chance that the statistician makes an error.
In Bayesian terms, the p-value from NHST is the probability that we observe the data (e.g., the differences between two sample means), assuming the null hypothesis is true. If we want to interpret the p-value in terms of evidence for a proposition, then we want the conditional error probability.
Sellke et al (2001) provided a calibration of p-values and, assuming that the prior probabilities of the null hypothesis and the alternative hypothesis are equal (that is, that each have a prior probability of 0.5), by using a formula provided by them (equation 3), we can correct our NHST p-value into a probability that can be interpreted as evidence in favor of the interpretation that the null hypothesis is true. In Bayesian terms this is called the posterior probability of the null hypothesis. The formula is
![\begin{align*} conditional \ error \ probability =\left \{ 1+ \left ( -e \cdot p \cdot ln \left [ p \right ]^{-1}\right )\right \}^{-1} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-09e06b0ea028cc8cfaf82e8001b59ad1_l3.png "Rendered by QuickLaTeX.com")
where e is Euler’s number, the base of the natural logarithm (ln), and p is the p-value from the NHST. This calibration works as long as  (Sellke et al 2001).
(Sellke et al 2001).
By convention we set the Type I error at 5% (cf Cohen 1994). How strong of evidence is a p-value near 5% against the null hypothesis being true, again, under the assumption that the prior probability of the null hypothesis being true is 50%? Using the above formula I constructed a plot of the calculated conditional error probability values against p-values (Fig 4).
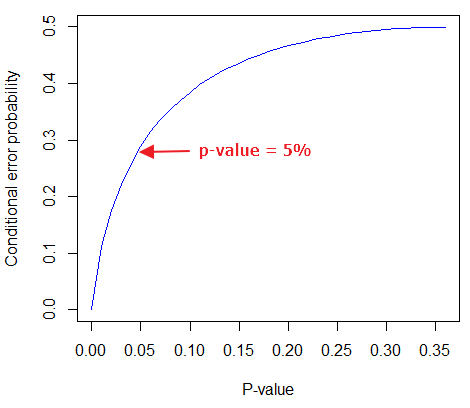
Figure 4. Conditional error probability values plotted against p-values.
As you can see, a p-value of 5% is not strong evidence at just 0.289. Not until p-values are smaller than 0.004 does the conditional error probability value dip below 0.05, suggesting strong evidence against the null hypothesis being true.
R note: For those of you keeping up with the R work, here’s the code for generating this plot. Text after “#” are comments and are not interpreted by R.
At the R prompt type each line
NHSTp = seq(0.00001,0.37,by=0.01) #create a sequence of numbers between 0.0001 and 0.37 with a step of 0.01 CEP = (1+(-1*exp(1)*NHSTp*log(NHSTp))^-1)^-1 #equation 3 from Sellke et al 2001 plot(NHSTp,CEP,xlab="P-value", ylab="Conditional error probability",type="l",col="blue")
Why is this important to me as a beginning student?
As we go forward I will be making statements about p-values and Type I error rates and null hypotheses and even such things as false positives and false negative. We need to start to grapple with what exactly can be said by p-values in the context of statistical inference, and to recognize that we will sometimes state conclusions that cut some corners when it comes to interpreting p-values. And yet, you (and all consumers of statistics!) are expected to recognize what p-values mean. Always.
The real meaning and interpretation of P-values
This is as good of a time as any to make some clarification about the meaning of p-value and the whole inference concept. Fisher indeed came up with the concept of the p-value, but its use as a decision criterion owes to others and Fisher disagreed strongly with use of the p-value in this way (Fisher 1955; Lehmann 1993).
Here are some common p-value corner-cutting statements to avoid using (after Goodman 2008; Held 2010). P-values are sometimes interpreted, incorrectly, as
Table. Incorrect interpretations of NHST p-values
- the probability of obtaining the observed data under the assumption of no real effect
- an observed type-I error rate
- the false discovery rate, i.e. the probability that a significant finding is a “false positive”
- the (posterior) probability of the null hypothesis.
So, if p-values don’t mean any of these things, what does a p-value mean? It means that we begin by assuming that there is no effect of our treatments — the p-value is then the chance we will get as large of a result (our test statistic) and the null hypothesis is true. Note that this definition does not include a statement about evidence of the null hypothesis being true. To get evidence of “truth” we need additional tools, like the Bayes Factor and the correction of the p-value to the conditional error probability (see above). Why not dump all of the NHST and go directly to a Bayesian perspective, as some advise? The single best explanation was embedded in the assumption we made about the prior probability in order to calculate the conditional error probability. We assumed the prior probability was 50%. For many, many experiments, that is simply a guess. The truth is we generally don’t know what the prior probability is. Thus, if this assumption is incorrect, then the justification for the formula by Sellke et al (2001) is weakened, and we are no closer to establishing evidence than before.
The take home message is that it is unlikely that a single experiment will provide strong evidence for the truth. Thus the message is repeat your experiments — and you already knew that! And the Bayesians can tell us that with the addition of more and more data reduces the effect of the particular value of the prior probability on our calculation of the conditional error probability. So, that’s the key to this controversy over the p-value.
Reporting p-values
Estimated p-values can never be zero. Students may come to use software that may return p-values like “0” — I’m looking at you Google Sheets re: default results from CHISQ.TEST() — but again, this does not mean the probability of the result is zero. The software simply reports values to two significant figures and failed to round. Some journals may recommend that 0 should be replaced by p < 0.01 or even < 0.05 inequalities, but the former lacks precision and the latter over-emphasizes the 5% Type I error rate threshold, the “statistical significance” of the result. In general, report p-value to three significant figures and four digits. If a p-value is small, use scientific notation and maintain significant digits. Thus, a p-value of 0.004955794 should be reported as 0.00496 and a p-value of 0.0679 should be reported as 0.0679. Use R’s signif() function, for example p-value reported as 6.334e-05, then
signif(6.334e-05,3) [1] 6.33e-05
Rounding and significant figures were discussed in Chapter 3.5. See Land and Altman (2015) for guidelines on reporting p-values and other statistical results.
Questions
- Revisit Figure 1 again and consider the following hypothesis — the sun will rise tomorrow.
- If we take the Frequentist position, what would the null hypothesis be?
- If we take the Bayesian approach, identify the prior probability.
- Which approach, Bayesian or Frequentist, is a better approach for testing this hypothesis?
- Consider the pediatrician who, upon receiving a chest X-ray for a child notes the left lung has a large irregular opaque area in the lower quadrant. Based on the X-ray and other patient symptoms, the doctor diagnoses pneumonia and prescribes a broad-spectrum antibiotic. Is the doctor behaving as a Frequentist or a Bayesian?
- With the p-value interpretations listed in the table above in hand, select an article from PLoS Biology, or any of your other favorite research journals, and read how the authors report results of significance testing. Compare the precise wording in the results section against the interpretative phrasing in the discussion section. Do the authors fall into any of the p-value corner-cutting traps?
Quiz Chapter 8.2
The controversy over proper hypothesis testing
Chapter 8 contents
- Introduction
- The null and alternative hypotheses
- The controversy over proper hypothesis testing<.span>
- Sampling distribution and hypothesis testing
- Tails of a test
- One sample t-test
- Confidence limits for the estimate of population mean
- References and suggested readings
7.6 – Confidence intervals
Quantifying uncertainty.
Although I’ve already presented the concept (eg, Chapter 3.4), and equations for confidence intervals of risk estimates (Chapter 7.4, Chapter 7.5), here, we expand on the idea of confidence intervals. Confidence intervals are a central part of meeting one of the main objectives of statistics, that is, estimation and communicating uncertainty with any reported estimate.
There are three components of statistical analysis
- Estimation
- Inference
- Modeling
Inference refers to statistical hypothesis testing — we ask questions of observations — do men (Rice et al 1999) and women (Fisher et al 2012) differ for blood glucose levels following a bout of aerobic exercise? T-tests, analysis of variance (ANOVA), chi-square, correlation, regression are types of statistical procedures used to do statistical inference. Modeling on the other hand refers to procedures used to relate cause and effect or for use in prediction of future values given new data. Many of the statistical procedures one uses for inference are also used to build statistical models (ANOVA, regression). Studies may intend to either test some hypothesis (inference) or to provide a predictive equation (modeling). But most studies that relate observations gathered from an experiment are obliged to also report statistics, and this is the realm of estimation. Estimates of the mean and standard deviation, for example, would be typical statistics one expects to find in a report. We call these descriptive statistics, and together with graphics, descriptive statistics are the chief way we describe our results.
Confidence intervals are crucial in statistics because they provide a range of values where the true population parameter is likely to fall, offering a more nuanced understanding of the estimate beyond just a single point value. Similarly, for statistical model model building, confidence intervals quantify the uncertainty inherent in data, providing a range of plausible values for model parameters rather than a single point estimate.
We will review how to calculate confidence intervals for proportions and for NNT. These intervals are available in epiR package and automatically returned in RcmdrPlugin.EBM.
Confidence interval for proportions
A proportion is the fraction of individuals in a population with some characteristic. The characteristic might be HIV positive for example. This would be called the population proportion and it would be a parameter of interest. In reality, we calculate a sample proportion and therefore estimate the population proportion with error. We can calculate the confidence interval (CI) of the proportion to communicate the precision of our estimate. For proportions, we use the binomial distribution — either a sample has the characteristic of interest or it does not — there are only two possibilities. There are a variety of ways to go here, and the simplest is to use a normal approximation. This will work well provided the sample size was reasonably large and the proportion is not close to zero or one, that is, we invoke the Central Limit Theorem here. Although the outcomes are binomial, the error is assumed to be normally distributed. The Wald confidence interval for p is

where  is the proportion of individuals with the characteristic (also called successes), z is the percentile from the normal distribution that corresponds to 1 – 1/2α. For 95% CI then α = 0.05 and z would be 1.965. (See standard normal table.) Of course, if making the normal approximation for the binomial is not appropriate, the CI is less than ideal. The binomial after all is a discrete distribution whereas the normal distribution is continuous, so errors will enter particularly for low sample numbers.
is the proportion of individuals with the characteristic (also called successes), z is the percentile from the normal distribution that corresponds to 1 – 1/2α. For 95% CI then α = 0.05 and z would be 1.965. (See standard normal table.) Of course, if making the normal approximation for the binomial is not appropriate, the CI is less than ideal. The binomial after all is a discrete distribution whereas the normal distribution is continuous, so errors will enter particularly for low sample numbers.
Other approaches may be used to get better estimates of CI for proportions, including Wilson score intervals and Jeffrey Intervals (Agresti and Coull 1998). See R package propCIs.
Because a statistic like the mean or a calculation of absolute or relative risk reduction are calculated from samples drawn from a population, the estimate comes with error. The error is basically this – if we calculate a statistic like number needed to treat (NNT) or its converse, the number needed to harm (NNH), we need to communicate to the reader how precise our estimate is. Estimation has to do with accuracy, error, and precision.
Confidence interval for ARR
The ARR is simply 
where  is the number of treated or exposed individuals for which the event occurred and
is the number of treated or exposed individuals for which the event occurred and  is the number of untreated or unexposed individuals which the event occurred.
is the number of untreated or unexposed individuals which the event occurred.
| Event happened | Event did not happen | |
| Treated or Exposed |
a | b |
| Control or Not exposed |
c | d |
Our data from example (Ch 7.5), were a = 612, b = 2192, c = 375, and d = 2543.

and the 95% confidence interval is then 
approximately. The “2” is only approximate; you need to use Z = 1.965, the value at probability value = 0.9725 (which comes from the Normal Table).
Confidence interval for NNT
For a sample of 100 people drawn at random from a population (which may number in the millions), then repeat the NNT calculation for a different sample of 100 people, do we expect the first and second NNT estimates to be EXACTLY the same number? No, but we do expect them to be close and we can define what we mean by close as we expect each estimate to be within certain limits. While we expect the second calculation to be close to the first estimate, we would be surprised if it was EXACTLY the same. And so, which is the correct estimate, the first or the second? They both are, in the sense that they both estimate the parameter NNT (a property of a population). But we can do better than two estimates. Confidence Intervals (CI) allow us to assign a probability to how certain we are about the statistic and whether it is likely to be close to the true value. We will
For CI of NNT, we need sample size for control and treatment groups; like all confidence intervals, we need to calculate the standard error of the statistic, in this, case, the standard error (SE) for NNT.
SE = sqrt(risk placebo * (1 - risk placebo) / (# in placebo group) + risk treatment * (1 - risk treatment) / (# in treatment group))
where SE is the standard error for NNT
The CI is approximately then 
* – the “2” is only approximate; you need to use Z = 1.965, the value at probability value = 0.9725 (by multiplying this, which comes from the Standard Normal Table).
Odds ratio Standard error and 95% confidence interval
Like any statistic we can calculate, an estimate of odds ratio should be accompanied by the confidence limit. The standard error may be calculated with the following formula

R code
seOdds <- sqrt(sum(1/612, 1/2192,1/375,1/2543))
where ln refers to the natural logarithm. An estimate for the 95% confidence interval is

where exp is the exponential function
![\[e^{x}\]](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-ba56dfb7fb0ca4b7a2eab4b0962b1c59_l3.png "Rendered by QuickLaTeX.com")
and ln is natural logarithm.
R code
exp(log(1.89,base=exp(1)) - 1.96*seOdds)
Our example the lower limit was 1.64. For the upper limit

Our example the upper limit was 2.19.
R code
exp(log(1.89,base=exp(1)) + 1.96*seOdds)
Thus, our estimate was 1.89 and the 95% confidence interval was 
which does not include one. Therefore, we conclude statistically different.
Note 1. A reminder, log() without specifying the base returns the natural logarithm. A better coding habit might suggest always specifying the base:
log(x, base = exp(1))P-values from confidence intervals
While we expect certain reporting criteria for published, it is not uncommon that one or more elements are missing. For example, while we show how to obtain confidence intervals, the p-values were not reported. We discuss statistical inference and p-values in detail in Chapter 8, but for now, a low p-value (typically < 0.05) indicates that the odds ratio (OR) is statistically significant, meaning the observed relationship between a factor and an outcome is unlikely to be due to random chance. An OR of the difference may not be reported, or, an inexact p-value is reported like “< 0.05,” but we “need” an exact p-value for our meta-analysis. A little math, and these missing statistics can be calculated.
Note 2. We illustrated how to calculate confidence intervals from p-values in Chapter 3.4 – Estimating parameters. See two helpful “how to” articles by Bland and Altman in 2011 BMJ (references listed in Chapter 3.6 – References).
We can use the OR example. We need to take the logarithm of ratios like OR or NNT or RRR. From above, we have the confidence intervals.
We need
The OR estimate,  , which was 1.89
, which was 1.89
lower and upper confidence intervals: 1.64 and 2.19, respectively.
the standard error, which can be calculated as 
the test statistic, 
and then the p-value, 
we would then report that the OR was not statistically different, p = 0.4044).
Questions
1. Instead of 95% confidence interval, obtain the 99% confidence interval for odds ratio 1.89.
Quiz Chapter 7.6
Confidence intervals
Chapter 7 contents
7.5 – Odds ratio
What are the odds.
We introduced the concept of odds 7.1 — Epidemiology definitions. As a reminder, odds are a way to communicate the chance (likelihood) that a particular event will take place. Odds are calculated as the number of individuals with the event divided by the number of individuals without the event.
Odds ratio definition: is a measure of effect size for the association between two binary (yes/no) variables. It is the ratio of the odds of an event occurring in one group to the odds of the same event happening in another group. The odds ratio (OR) is a way to quantify the strength of association between one condition and another.
Note 1: Effect size — the size of the difference between groups — is discussed further in Chapter 9.2 and Chapter 11.4.
And note, it’s association, not correlation. In statistics, correlation is a specific kind of relationship (linear) among the variables, whereas “association” means there is some relationship between the variables without specifying the shape of the relationship.
How are odds ratios calculated? The probabilities are conditional; recall that conditional probability of some event A, given the occurrence of some other event B.
Let  equal probability of the event occurring (y = Yes) in A,
equal probability of the event occurring (y = Yes) in A,  equal probability of the event not occurring (n = No) in A,
equal probability of the event not occurring (n = No) in A,  equal probability of the event occurring in B, and
equal probability of the event occurring in B, and  equal probability of the event not occurring in B.
equal probability of the event not occurring in B.
| A | |||
| Yes | No | ||
| B | Yes | |
|
| No | |
|
|
These sum to one: 
The conditional probabilities are
| A | |||
| Yes | No | ||
| B | Yes |  |
 |
| No |  |
 |
|
and finally then, the odds ratio (OR) is

If you have the raw numbers you can calculate the odds ratio directly, too.
| A | |||
| Yes | No | ||
| B | Yes | a | b |
| No | c | d | |
and the odds ratio is then

or, equivalently

Example.
Comparing proportions is a frequent need in court. Gray (2002) provided an example from Title IX of the Education Act of 1972 case Cohen v. Brown University. Under the Act, discrimination based on gender is prohibited. The case concerned participation in collegiate athletics by women. The case data were that of the 5722 undergraduate students, 51% were women, but of the 987 athletes, only 38% were women. A mosaic plot shows graphically these proportions (Fig 1, males in red bars, females in yellow bars).
Figure 1. Mosaic plot of athletes to non-athletes in college. Males red, females yellow, data from Gray 2002.
Alternatively, use a Venn diagram to describe the distribution (Fig 2). Circles that overlap show regions of commonality.
Figure 2. Venn Diagram of athletes to non-athletes in college. Female athletes (n = 375), male athletes (n = 612), data from Gray 2002.
where the orange region

R code for the Venn diagram was
library(VennDiagram)
area1 = 5722
area2 = 987
cross.area = 375
draw.pairwise.venn(area1,area2,cross.area,category=c("Students","Athletes"),
euler.d = TRUE, scaled = TRUE, inverted = FALSE, print.mode = "percent",
fill=c("Red","Yellow"),cex = 1.5, lty="blank", cat.fontfamily = rep("sans", 2),
cat.cex = 1.7, cat.pos = c(0, 180), ext.pos=0)
The question raised before the court was whether these proportions meet the demand of “substantially proportionate.” What exactly the law means by “substantially proportionate” was left to the courts and the lawyers to work out (Gray 2002). Title IX suggests that “substantially proportionate” is a statistical problem and the two sides of the argument must address the question from that perspective.
What is the chance that an undergraduate student was an athlete and female? 38% And the chance that an undergraduate student was an athlete and male? 62% Clearly 38% is not 62%; did the plaintiffs have a case?
Graphs like Figure 1 and Figure 2 help communicate but can’t provide a sense of whether the differences are important. Let’s start by looking at the numbers. Working with the proportions we have the following break down for numbers of students (Table 1) or as proportions (Table 2).
Table 1. Gray’s raw data displayed in a 2 x 2 format.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 612 | 2192 |
| Female | 375 | 2543 | |
Together, the numbers total 5,722.
The Odds Ratio (OR) would be

Or from the proportions (Table 2)
Table 2. Data from Table 1 as proportions.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 0.107 | 0.383 |
| Female | 0.066 | 0.444 | |
adding all of these frequencies together equal 1. Carry out the calculation of odds (Table 3), the conditional probabilities (in bold).
Table 3. Odds calculated from Table 2 inputs.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Male | 0.218
|
0.782
|
| Female | 0.129
|
0.871
|
|




Calculate the odds ratio

Thankfully, whether we use the raw number format or the proportion format, we got the same results!
Odds ratio interpretation.
Because the Odds Ratio (OR) was greater than 1, males students were more likely to be athletes than female students. If there was no difference in proportion of male and female athletes, the odds ratio would be close to one. That is a test of statistical inference (e.g., a contingency table), but for now, if one is included in the confidence interval, then this would be evidence that there was no difference between the proportions.
And in R? Simple enough, just create a matrix then apply the Fisher test. which we will discuss further in Chapter 9.5.
title9 <- matrix(c(612, 2192, 375, 2543), nrow=2)) fisher.test(title9)
and results
p-value < 2.2e-16 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 1.641245 2.185576 sample estimates: odds ratio 1.893143
Thankfully, they agree. But note, we now have confidence intervals and a p-value, which we use to conduct inference: were the odds “significantly different from 1?” We would conclude, yes! Between the lower limit (1.64) and the upper limit (2.19), the value “1” was excluded. Moreover, the p-value at 2.2e-16 was much less than the standard type I error cut-off of 5% (see Chapter 8).
Before we leave the interpretation, sometimes a calculated odds-ratio is less than one. If our calculated odds ratio for the Title IX case described in Table 1 was less than 1, (say, the numbers were flipped, Table 4) we then the interpretation would be females were more likely to be athletes on college campus.
Table 4. Table 1 data, but order of entry changed.
| Athletes | |||
| Yes | No | ||
| Undergraduates | Female | 375 | 2543 |
| Male | 612 | 2192 | |
Now, calculating the odds via Fisher exact test, the odds ratio is less than one (0.53):
Fisher's Exact Test for Count Data p-value < 2.2e-16 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 0.4575452 0.6092936 sample estimates: odds ratio 0.5282222
Note this result is for the same data (Table 1 vs Table 4), just the order by which the groups are specified changed. Of course they are related to each other mathematically, and in a simple way. Note that taking the inverse (reciprocal) odds ratio.

will return the comparison we wanted in the first place — the odds a student athlete was male. As long as you keep track of the comparison, of the groups, it may be easier to communicate results when the reported odds ratio is greater than one.
Relative risk v. odds ratio.
We introduced another way to quantify this association as the Relative Risk (RR) and Absolute Risk Reductions in the previous section. Both can be used to describe the risk of the treatment (exposed) group relative to the control (nonexposed) group. RR is the ratio the treated to control group. OR is the ratio between odds of treated (exposed) and control (nonexposed). What’s the difference? OR is more general — it can be used in situations in which the researcher chooses the number of affected individuals in the groups and, therefore, the base rate or prevalence of the condition in the population is not known or is not representative of the population, whereas RR is appropriate when prevalence is known (this is a general point, but see Schechtman 2002 for a nice discussion).
The odds ratio is related to relative risk, but not over the entire range of possible risk. Odds of an event is simply the number of individuals with the event divided by the number without the event. Odds of an event therefore can range from zero (event cannot occur) to infinity (event must occur). For example, odds of eight (1.89:1) means that nearly two male students were student athletes at Brown University for every one female student.
In contrast, the risk of an event occurring is the number of individuals with the event divided by the total number of people at risk of having that event. Risk is expressed as a percentage (Davies et al 1998). Thus, for our example, odds of 1.89:1 correspond to a risk of 1.89 divided by (1 + 1.89) equals 65%.
To get the relative risk we can use

or 1.7% for our example.
In this example we could use either odds or relative risk; the key distinction is that we knew how many events happened in both groups. If this information is missing for one group (e.g., control group of the case-control design), then only the odds ratio would be appropriate.
From cumulative wisdom in the literature (e.g., Tamhane et al 2107), if prevalence is less than ten percent, OR ≈ RR. We can relate RR and OR as

where n11 and n21 are the frequency with the condition for group 1 and group 2, respectively, and n12 and n22 are the frequency without the condition for group 1 and group 2, respectively. For the examples on this page group 1 is the treatment group and group 2 is the control group.
Hazard ratio
The hazard ratio is the ratio of hazard rates. Hazard rates are like the relative risk rates, but are specific to a period of time. Hazard rates come from a technique called Survival Analysis (introduced in Chapter 20.9). Survival analysis can be thought of as following a group of subjects over time until something (the event) happens. By following two groups, perhaps one group exposed to a suspected carcinogen vs. another group matched in other respects except the exposure, at the end of the trial, we’ll have two hazard rates: the rate for the exposed group and the rate for the control group. If there is no difference, then the hazard ratio will be one.
Hazard ratios are more appropriate for clinical trials; relative risk is more appropriate for observational studies.
For a hazard ratio, it is often easier to think of it as a probability (between 0 to 1). To translate a hazard ratio to a probability use the following equation

Questions
- Distinguish between odds ratio, relative risk, and hazard ratio.
- Refer to problem 1 introduced in 7.4 – Epidemiology: Relative risk and absolute risk, explained.
Quiz Chapter 7.5
Odds ratio
Chapter 7 contents
7.4 – Epidemiology: Relative risk and absolute risk, explained
Risk communication.
Epidemiology is the study of patterns of health and illness of populations. An important task in an epidemiology study is to identify risks associated with disease. Epidemiology is a crucial discipline used to inform about possible effective treatment approaches, health policy, and about the etiology of disease.
Please review terms presented in section 7.1 before proceeding. RR and AR are appropriate for cohort-control and cross-sectional studies (see 2.4 and 5.4) where base rates of exposure and unexposed or numbers of affected and non-affected individuals (prevalence) are available. Calculations of relative risk (RR) and relative risk reduction (RRR) are specific to the sampled groups under study whereas absolute risk (AR) and absolute risk reduction (ARR) pertain to the reference population. Relative risks are specific to the study, absolute risks are generalized to the population. Number needed to treat (NNT) is a way to communicate absolute risk reductions.
An example of ARR and RRR risk calculations using natural numbers.
Clinical trials are perhaps the essential research approach (Sibbald and Roland 1998; Sylvester et al 2017); they are often characterized with a binary outcome. Subjects either get better or they do not. There are many ways to represent risk of a particular outcome, but where possible, using natural numbers is generally preferred as a means of communication, particularly to the general public. Consider the following example (pp 34-35, Gigerenzer 2015): What is the benefit of taking a cholesterol-lowering drug, Pravastatin, on the risk of deaths by heart attacks and other causes of mortality? Press releases (e.g., Maugh 1995), from the study stated the following:
“… the drug pravastatin reduced … deaths from all causes 22%”
A subsequent report (Skolbekken 1998) presented the following numbers (Table 1).
Table 1. Reduction in total mortality (5 year study) for people who took Pravastatin compared to those who took placebo.
| Deaths per 1000 people with high cholesterol (> 240 mg/dL) |
No deaths | Cumulative incidence |
||
| Treatment | Pravastatin
(n = 3302) |
a= 32 |
b= 3270 |
CIe |
| Placebo
(n = 3293) |
c= 41 |
d= 3252 |
CIu | |
where cumulative incidence refers to the number of new events or cases of disease divided by the total number of individuals in the population at risk.
Do the calculations of risk
The risk reduction (RR), or the number of people who die without treatment (placebo) minus those who die with treatment (Pravastatin), 

and the cumulative incidence in the exposed (treated) group, CIe, is  , and cumulative incidence in the unexposed (control) group, CIu, is
, and cumulative incidence in the unexposed (control) group, CIu, is  . We can calculate another statistic called the risk ratio,
. We can calculate another statistic called the risk ratio,

because the risk ratio is less than one, we interpret that statins reduce the risk of mortality from heart attack. In other words, statins lowered the risk by 0.78.
But is this risk reduction meaningful?
Now, consider the absolute risk reduction (ARR) is 
Relative risk reduction, or the absolute risk reduction divided by the proportion of patients who die without treatment, is 
Conclusion: high cholesterol may contribute to increased risk of mortality, but the rate is very low in the population as a whole (the ARR).
Another useful way to communicate benefit is to calculate the Number Needed to Treat (NNT), or the number of people who must receive the treatment to save (benefit) one person. The ideal NNT is a value of one (1), which would be interpreted as everyone improves who receives the treatment. By definition, NNT must be positive; however, a resulting negative NNT would suggest the treatment may cause harm, i.e., number needed to harm (NNH).
For this example, the NNT is

therefore, to benefit one person, 111 need to be treated. The flip side of the implications of NNT, although one person may benefit by taking the treatment, 110 ( ) will take the treatment, but will NOT RECEIVE THE BENEFIT, but do potentially get any side effect of the treatment.
) will take the treatment, but will NOT RECEIVE THE BENEFIT, but do potentially get any side effect of the treatment.
Confidence interval for NNT is derived from the Confidence interval for ARR.
For a sample of 100 people drawn at random from a population (which may number in the millions), then repeat the NNT calculation for a different sample of 100 people, do we expect the first and second NNT estimates to be exactly the same number? No, but we do expect them to be close and we can define what we mean by close as we expect each estimate to be within certain limits. While we expect the second calculation to be close to the first estimate, we would be surprised if it was exactly the same. And so, which is the correct estimate, the first or the second? They both are, in the sense that they both estimate the parameter NNT (a property of a population).
We use confidence interval to communicate where we believe the true estimate for NNT to be. Confidence Intervals (CI) allow us to assign a probability to how certain we are about the statistic and whether it is likely to be close to the true value (Altman 1998, Bender 2001). We will calculate the 95% CI for the ARR using the Wald method, then take the inverse of these estimates for our 95% CI. The Wald method assumes normality.
For CI of ARR, we need sample size for control and treatment groups; like all confidence intervals, we need to calculate the standard error of the statistic, in this, case, the standard error (SE) for ARR is approximately

where SE is the standard error for ARR. For our example, we have

The 95% CI for ARR is approximately 
For the Wald estimate, replace the 2 with  , which comes from the normal table for z at
, which comes from the normal table for z at 
(why the 2 in the equation? Because it is plus or minus so we divide the frequency 0.95 in half) and for our example, we have 
and the inverse for NNT CI is 
Our example exemplifies the limitation of the Wald approach (cf. Altman 1998): our confidence interval includes zero, and doesn’t even include our best estimate of NNT (111).
Note 1: By now I trust you can see differences for results by direct input of the numbers into R and what you get by the natural numbers approach. In part this is because we round in our natural number calculations — remember, while it makes more sense to communicate about whole numbers (people) and not fractions (fractions of people!), rounding through the calculations adds error to the final value. As long as you know the difference and the relevance between approximate and exact solutions, this shouldn’t cause concern.
Software: epiR.
R has many epidemiology packages, epiR and epitools are two. Most of the code presented stems from epiR.
We need to know about our study design in order to tell the functions which statistics are appropriate to estimate. For our statin example, the design was prospective cohort (i.e., cohort.count in epiR package language), not case-control or cross-sectional (review in Chapter 5.4).
library(epiR)
Table1 <- matrix(c(32,3270,41,3252), 2, 2, byrow=TRUE, dimnames = list(c("Statin", "Placebo"), c("Died", "Lived")))
Table1
Died Lived
Statin 32 3270
Placebo 41 3252
epi.2by2(Table1, method="cohort.count", outcome = "as.columns")
R output
Outcome + Outcome - Total Inc risk *
Exposed + 32 3270 3302 0.97 (0.66 to 1.37)
Exposed - 41 3252 3293 1.25 (0.89 to 1.69)
Total 73 6522 6595 1.11 (0.87 to 1.39)
Point estimates and 95% CIs:
-------------------------------------------------------------------
Inc risk ratio 0.78 (0.49, 1.23)
Inc odds ratio 0.78 (0.49, 1.24)
Attrib risk in the exposed * -0.28 (-0.78, 0.23)
Attrib fraction in the exposed (%) -28.48 (-103.47, 18.88)
Attrib risk in the population * -0.14 (-0.59, 0.32)
Attrib fraction in the population (%) -12.48 (-37.60, 8.05)
-------------------------------------------------------------------
Uncorrected chi2 test that OR = 1: chi2(1) = 1.147 Pr>chi2 = 0.284
Fisher exact test that OR = 1: Pr>chi2 = 0.292
Wald confidence limits
CI: confidence interval
* Outcomes per 100 population units
The risk ratio we calculated by hand is shown in green in the R output, along with other useful statistics (see ?epi2x2 for help with these additional terms) not defined in our presentation.
We explain results of chi-square goodness of fit (Ch 9.1) and Fisher exact (Ch 9.5) tests in Chapter 9. Suffice to say here, we interpret the p-value (Pr) = 0.284 and 0.292 to indicate that there is no association between mortality from heart attacks with or without the statin (i.e., the Odds Ratio, OR, not statistically different from one).
Wait! Where’s NNT and other results?
Use another command in epiR package, epi.tests(), to determine the specificity, sensitivity, and positive (or negative) predictive value.
epi.tests(Table1)
and R returns
Outcome + Outcome - Total Test + 32 3270 3302 Test - 41 3252 3293 Total 73 6522 6595 Point estimates and 95% CIs: -------------------------------------------------------------- Apparent prevalence * 0.50 (0.49, 0.51) True prevalence * 0.01 (0.01, 0.01) Sensitivity * 0.44 (0.32, 0.56) Specificity * 0.50 (0.49, 0.51) Positive predictive value * 0.01 (0.01, 0.01) Negative predictive value * 0.99 (0.98, 0.99) Positive likelihood ratio 0.87 (0.67, 1.13) Negative likelihood ratio 1.13 (0.92, 1.38) False T+ proportion for true D- * 0.50 (0.49, 0.51) False T- proportion for true D+ * 0.56 (0.44, 0.68) False T+ proportion for T+ * 0.99 (0.99, 0.99) False T- proportion for T- * 0.01 (0.01, 0.02) Correctly classified proportion * 0.50 (0.49, 0.51) -------------------------------------------------------------- * Exact CIs
Additional statistics are available by saving the output from epi2x2() or epitests() to an object, then using summary(). For example save output from epi.2by2(Table1, method="cohort.count", outcome = "as.columns") to object myEpi, then
summary(myEpi)
look for NNT in the R output
$massoc.detail$NNT.strata.wald
est lower upper
1 -362.377 -128.038 436.481
Thus, the NNT was 362 (compared to 111 we got by hand) with 95% Confidence interval between -436 and +128 (make it positive because it is a treatment improvement).
Note 2: Strata (L. layers), refer to subgroups, for example, sex or age categories (see discussion in Ch05.4). Our examples here are not presented as subgroup analysis, but epiR reports by name strata.
epiR reports a lot of additional statistics in the output and for clarity, I have not defined each one, just the basic terms we need for BI311. As always, see help pages (e.g., ?epi.2x2 or ?epitests)for more information about structure of an R command and the output.
We’re good, but we can work the output to make it more useful to us.
Improve output from epiR.
For starters, if we set interpret=TRUE instead of the default, interpret=FALSE, epiR will return a richer response.
fit <- epi.2by2(dat = as.table(Table1), method = "cohort.count", conf.level = 0.95, units = 100, interpret = TRUE, outcome = "as.columns") fit
R output. In addition to the table of coefficients (above), interpret=TRUE provides more context, shown below
Measures of association strength: The outcome incidence risk among the exposed was 0.78 (95% CI 0.49 to 1.23) times less than the outcome incidence risk among the unexposed. The outcome incidence odds among the exposed was 0.78 (95% CI 0.49 to 1.24) times less than the outcome incidence odds among the unexposed. Measures of effect in the exposed: Exposure changed the outcome incidence risk in the exposed by -0.28 (95% CI -0.78 to 0.23) per 100 population units. -28.5% of outcomes in the exposed were attributable to exposure (95% CI -103.5% to 18.9%). Number needed to treat for benefit (NNTB) and harm (NNTH): The number needed to treat for one subject to be harmed (NNTH) is 362 (NNTH 128 to infinity to NNTB 436). Measures of effect in the population: Exposure changed the outcome incidence risk in the population by -0.14 (95% CI -0.59 to 0.32) per 100 population units. -12.5% of outcomes in the population were attributable to exposure (95% CI -37.6% to 8.1%).
That’s quite a bit. Another trick is to get at the table of results. We install a package called broom, which includes a number of ways to handle output from R functions, including those in the epiR package. Broom takes from the TidyVerse environment; tables are stored as tibbles.
library(broom) # Test statistics tidy(fit, parameters = "stat")
R output
# A tibble: 3 × 4 term statistic df p.value <chr> <dbl> <dbl> <dbl> 1 chi2.strata.uncor 1.15 1 0.284 2 chi2.strata.yates 0.909 1 0.340 3 chi2.strata.fisher NA NA 0.292
We can convert the tibbles into our familiar data.frame format, and then select only the statistics we want.
# Measures of association fitD <- as.data.frame(tidy(fit, parameters = "moa")); fitD
R output, all 15 measures of association!
term estimate conf.low conf.high 1 RR.strata.wald 0.7783605 0.4914679 1.23272564 2 RR.strata.taylor 0.7783605 0.4914679 1.23272564 3 RR.strata.score 0.8742994 0.6584540 1.10340173 4 OR.strata.wald 0.7761915 0.4876209 1.23553616 5 OR.strata.cfield 0.7761915 NA NA 6 OR.strata.score 0.7761915 0.4894450 1.23093168 7 OR.strata.mle 0.7762234 0.4718655 1.26668220 8 ARisk.strata.wald -0.2759557 -0.7810162 0.22910484 9 ARisk.strata.score -0.2759557 -0.8000574 0.23482532 10 NNT.strata.wald -362.3770579 -128.0383246 436.48140194 11 NNT.strata.score -362.3770579 -124.9910314 425.84844829 12 AFRisk.strata.wald -0.2847517 -1.0347210 0.18878949 13 PARisk.strata.wald -0.1381661 -0.5933541 0.31702189 14 PARisk.strata.piri -0.1381661 -0.3910629 0.11473067 15 PAFRisk.strata.wald -0.1248227 -0.3760279 0.08052298
We can call out just the statistics we want from this table by calling to the specific elements in the data.frame (rows, columns).
fitD[c(1,4,7,9,12),]
R output
term estimate conf.low conf.high 1 RR.strata.wald 0.7783605 0.4914679 1.2327256 4 OR.strata.wald 0.7761915 0.4876209 1.2355362 7 OR.strata.mle 0.7762234 0.4718655 1.2666822 9 ARisk.strata.score -0.2759557 -0.8000574 0.2348253 12 AFRisk.strata.wald -0.2847517 -1.0347210 0.1887895
Software: epitools.
Another useful R package for epidemiology is epitools, but it comes with it’s own idiosyncrasies. We have introduced the standard 2X2 format, with a, b, c, and d cells defined as in Table 1, above. However, epitools does it differently, and we need to update the matrix. By default, epitools has the unexposed group (control) in the first row and the non-outcome (no disease) is in the first column. To match our a,b,c, and d matrix, use the epitools command to change this arrangement with the rev() argument. Now, the analysis will use the contingency table on the right where the exposed group (treatment) is in the first row and the outcome (disease) is in the first column (h/t M. Bounthavong 2021). Once that’s accomplished, epitools returns what you would expect.
Calculate relative risk
risk1 <- 32 / (3270 + 32) risk2 <- 41 / (3525 + 41) risk1 - risk2
and R returns
-0.00180638
odds ratio
library(epitools)
oddsratio.wald(Table1, rev = c("both"))
and R returns
$data
Outcome
Predictor Disease2 Disease1 Total
Exposed2 517 36 553
Exposed1 518 11 529
Total 1035 47 1082
$measure
odds ratio with 95% C.I.
Predictor estimate lower upper
Exposed2 1.0000000 NA NA
Exposed1 0.3049657 0.1535563 0.6056675
$p.value
two-sided
Predictor midp.exact fisher.exact chi.square
Exposed2 NA NA NA
Exposed1 0.0002954494 0.0003001641 0.0003517007
odds ratio highlighted in green.
Software: OpenEpi.
R is fully capable of delivering the calculations you need, but sometimes you just want a quick answer. Online, the OpenEpi tools at https://www.openepi.com/ can be used for homework problems. For example, working with count data in 2 X 2 format, select Counts > 2X2 table from the side menu to bring up the data form (Fig 1).
Figure 1. Data entry for 2X2 table at openepi.com.
Once the data are entered, click on the Calculate button to return a suite of results (Fig 2).
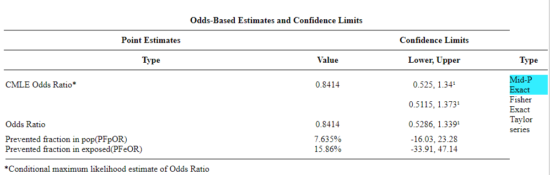
Figure 2. Results for 2X2 table at openepi.com.
Software: RcmdrPlugin.EBM
Note: Fall 2023 — I have not been able to run the EBM plugin successfully! Simply returns an error message — — on data sets which have in the past performed perfectly. Thus, until further notice, do not use the EBM plugin. Instead, use commands in the epiR package.
This isn’t the place nor can I be the author to discuss what evidence based medicine (EBM) entails (cf. Masic et al. 2008), or what its shortcomings may be (Djulbegovic and Guyatt 2017). Rcmdr has a nice plugin, based on the epiR package, that will calculate ARR, RRR and NNT as well as other statistics. The plugin is called RcmdrPlugin.EBM
install.packages("RcmdrPlugin.EBM", dependencies=TRUE)
After acquiring the package, proceed to install the plug-in. Restart Rcmdr, then select Tools and Rcmdr Plugins (Fig 3).
Figure 3. Rcmdr: Tools → Load Rcmdr plugins…
Find the EBM plug-in, then proceed to load the package (Fig 4).
Figure 4. Rcmdr plug-ins available (after first download the files from an R mirror site).
Restart Rcmdr again and the menu “EBM” should be visible in the menu bar. We’re going to enter some data, so choose the Enter two-way table… option in the EBM plug-in (Fig 5)
Figure 5. R Commander EBM plug-in, enter 2X2 table menus.
To review, we have the following problem, illustrated with natural numbers and probability tree (Fig 6).
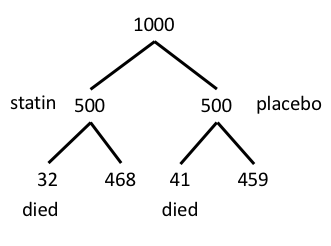
Figure 6. Illustration of probability tree for the statin problem.
Now, let’s enter the data into the EBM plugin. For the data above I entered the counts as
| Lived | Died | |
| Statin | 468 | 32 |
| Placebo | 459 | 41 |
and selected the “Therapy” medical indicator (Fig 7).
Figure 7. EBM plugin with two-way table completed for the statin problem.
The output from EBM plugin was as follows. I’ve added index numbers in brackets so that we can point to the output that is relevant for our worked example here.
(1) .Table <- matrix(c(468,32,459,41), 2, 2, byrow=TRUE, dimnames = list(c('Drug', 'Placebo'), c('Lived', 'Dead')))
(2) fncEBMCrossTab(.table=.Table, .x='', .y='', .ylab='', .xlab='', .percents='none', .chisq='1', .expected='0', .chisqComp='0', .fisher='0', .indicators='th', .decimals=2)
R output begins by repeating the commands used, here marked by lines (1) and (2). The statistics we want follow in the next several lines of output.
(3) Pearson's Chi-squared test data: .Table X-squared = 1.197, df = 1, p-value = 0.2739
(4) # Notations for calculations Event + Event -Treatment "a" "b" Control "c" "d"
(5)# Absolute risk reduction (ARR) = -1.8 (95% CI -5.02 - 1.42) %. Computed using formula: [c / (c + d)] - [a / (a + b)]
(6)# Relative risk = 1.02 (95% CI 0.98 - 1.06) %. Computed using formula: [c / (c + d)] / [a / (a + b)]
(7)# Odds ratio = 1.31 (95% CI 0.81 - 2.11). Computed using formula: (a / b) / (c / d)
(8) # Number needed to treat = -55.56 (95% CI 70.29 - Inf). Computed using formula: 1 / ARR
9)# Relative risk reduction = -1.96 (95% CI -5.57 - 1.53) %. Computed using formula: { [c / (c + d)] - [a / (a + b)] } / [c / (c + d)]
(10)# To find more about the results, and about how confidence intervals were computed, type ?epi.2by2 . The confidence limits for NNT were computed as 1/ARR confidence limits. The confidence limits for RRR were computed as 1 - RR confidence limits.
end R output
In summary, we found no difference between statin and placebo (P-value = 0.2739) and ARR of -1.8%
Questions.
Data from a case-control study on alcohol use and esophageal cancer (Tuyns et al (1977), example from Gerstman 2014). Cases were men diagnosed with esophageal cancer from a region in France. Controls were selected at random from electoral lists from the same geographical region.
| Esophageal cancer | |||
|
Alcohol grams/day |
Cases | Noncases |
Total |
| > 80 | 96 | 109 |
205 |
|
< 80 |
104 |
666 |
770 |
| Total | 200 | 775 | 975 |
- What was the null hypothesis? Be able to write the hypothesis in symbolic form and as a single sentence.
- What was the alternative hypothesis? Be able to write the hypothesis in symbolic form and as a single sentence.
- What was the observed frequency of subjects with esophageal cancer in this study? And the observed frequency of subjects without esophageal cancer?
- Estimate Relative Risk, Absolute Risk, NNT, and Odds ratio?
- Which is more appropriate, RR or OR? Justify your decision.
- The American College of Obstetricians and Gynecologists recommends that women with an average risk of breast cancer (BC) over 40 get an annual mammogram. Nationally, the sensitivity of mammography is about 68% and specificity of mammography is about 75%. Moreover, mammography involves exposure of women to radiation, which is known to cause mutations. Given that the prevalence of BC in women between 40 and 49 is about 0.1%, please evaluate the value of this recommendation by completing your analysis.
A) In this age group, how many women are expected to develop BC?
B) How many False negative would we expect?
C) How many positive mammograms are likely to be true positives? - “Less than 5% of women with screen-detectable cancers have their lives saved,” (quote from BMC Med Inform Decis Mak. 2009 Apr 2;9:18. doi: 10.1186/1472-6947-9-18): Using the information from question 5, What is the Number Needed to Treat for mammography screening?
Quiz Chapter 7.4
Epidemiology: Relative risk and absolute risk, explained
Chapter 7 contents
- Probability, Risk Analysis
- Epidemiology definitions
- Epidemiology basics
- Conditional Probability and Evidence Based Medicine
- Epidemiology: Relative risk and absolute risk, explained
- Odds ratio
- Confidence intervals
- References and suggested readings
7.3 – Conditional Probability and Evidence Based Medicine
- Conditional probability and risk communication
- Probability and independent events
- Example of multiple, independent events
- Probabilistic risk analysis
- Conditional probability of non-independent events
- Diagnosis from testing
- Standard million
- Per capita rate
- Practice and introduce PPV and Youden’s J
- Evidence Based Medicine
- Software
- Example
- Questions
- Quiz
- Chapter 7 contents
Conditional probability and risk communication.
Conditional probabilities can be used to accurately and effectively convey the risk of specific health outcomes to patients and the public. Tools introduced in this chapter help move from an initial assessment of disease risk to a revised probability after a test result is returned. Although there are other interpretations, here we frame EBM — evidence-based-medicine — as a form of Bayesian decision-making.
Chapter 7.3 covers a lot of ground. We begin by addressing how probability of multiple events are calculated assuming each event is independent. The assumption of independence is then relaxed, and how to determine probability of an event happening given another event has already occurred, conditional probability, is introduced. Use of conditional probability to interpret results of a clinical test are also introduced, along with the concept of EBM. We also introduce Bayes’ rule and Bayesian probability.
Probability and independent events.
Probability distributions are mathematical descriptions of the probabilities of how often different possible outcomes occur. We also introduced basic concepts related to working with the probabilities involving more than one event.
For review, for independent events, you multiply the individual chance that each event occurs to get the overall probability.
Example of multiple, independent events.

Figure 1. Now that’s a box full of kittens. Creative Commons License, source: https://www.flickr.com/photos/83014408@N00/160490011.
What is the chance of five kittens in a litter of five to be of the same sex? In feral cat colonies, siblings in a litter share the same mother, but not necessarily the same father, superfecundation. Singleton births are independent events, thus the probability of the first kitten is female is 50%; the second kitten is female, also 50%; and so on. We can multiply the independent probabilities (hence, the multiplicative rule), to get our answer:
kittens <- c(0.5, 0.5, 0.5, 0.5, 0.5) prod(kittens) [1] 0.03125
Probabilistic risk analysis.
Risk analysis is the use of information to identify hazards and to estimate the risk. A more serious example. Consider the 1986 Space Shuttle Challenger Disaster (Hastings 2003). Among the crew killed was Ellison Onizuka, the first Asian American to fly in space (Fig. 2, first on left back row). Onizuka was born and raised on Hawai`i and graduated from Konawaena High School in 1964.

Figure 2. STS-51-L crew: (front row) Michael J. Smith, Dick Scobee, Ronald McNair; (back row) Ellison Onizuka, Christa McAuliffe, Gregory Jarvis, Judith Resnik. Image by NASA – NASA Human Space Flight Gallery, Public Domain.
The shuttle was destroyed just 73 seconds after lift off (Fig 3).

Figure 3. Space Shuttle Challenger launches from launchpad 39B Kennedy Space Center, FL, at the start of STS-51-L. Hundreds of shorebirds in flight. Image by NASA – NASA Human Space Flight Gallery, Public Domain.
This next section relies on material and analysis presented in the Rogers Commission Report June 1986. NASA had estimated that the probability of one engine failure would be 1 in 100 or 0.01; two engine failures would mean the shuttle would be lost. Thus, the probability of two rockets failing at the same time was calculated as 0.01 X 0.01, which is 0.0001 or 0.01%.
NASA had planned to fly the fleet of shuttles 100 times per year, which would translate to a shuttle failure once in 100 years. The Challenger launch on January 28, 1986, represented only the 25th flight of the shuttle fleet.
One difference on launch day was that the air temperature at Cape Canaveral was quite low for that time of year, as low as 22 °F overnight.
Attention was pointed at the large O-rings in the boosters (engines). In all, there were six of these O-rings. Testing suggested that, at the colder air temperatures, the chance that one of the rings would fail was 0.023. Thus, the chance of success was only 0.977. Assuming independence, what is the chance that the shuttle would experience O-ring failure?
shuttle <- c(0.977, 0.977, 0.977, 0.977, 0.977, 0.977) #probability of success then was prod(shuttle) [1] 0.869 #and therefore probability of failure was 1 - prod(shuttle) [1] 0.1303042
Conditional probability of non-independent events.
But in many other cases, independence of events cannot be assumed. The probability of an event given that another event has occurred is referred to as conditional probability. Conditional probability is used extensively to convey risk. We’ve touched on some of these examples already:
- the risk of subsequent coronary events given high cholesterol;
- the risk of lung cancer given a person smokes tobacco;
- the risk of mortality from breast cancer given that regular mammography screening was conducted.
There are many, many examples in medicine, insurance, you name it. It is even an important concept that judges and lawyers need to be able to handle (e.g., Berry 2008).
A now famous example of conditional probability in the legal arena came from arguments over the chance that a husband or partner who beats his wife will subsequently murder her — this was an argument raised by the prosecution during pre-trial in the 1995 OJ Simpson trial (The People of the State of California v. Orenthal James Simpson), and successfully argued by O.J. Simpson’s attorneys… judge ruled in favor of the defense and evidence of OJ Simpson’s prior abuse were not included in trial). Gigerenzer (2002) and others have called this reverse Prosecutor’s Fallacy, where the more typical scenario is that the prosecution provides a list of probabilities about characteristics of the defendant, leaving the jury to conclude that no one else could have possibly fit the description.
In the OJ Simpson case, the argument went something like this. From the CDC we find that an estimated 1.3 million women are abused each year by their partner or former partner; each year about 1000 women are murdered. One thousand divided by 1.3 million is a small number, so even when there is abuse the argument goes, 99% of the time there is not murder. The Simpson judge ruled in favor of the defense and much of the evidence of abuse was excluded.
Something is missing from the defense’s argument. Nicole Simpson did not belong to a population of battered women — she belonged to the population of murdered women. When we ask, if a woman is murdered, what is the chance that she knew her murderer, we find that more than 55% knew their murderer — and of that 55%, 93% were killed by a current partner. The key is Nicole Simpson (and Ron Goldman) was murdered and OJ Simpson was an ex-partner who had been guilty of assault against Nicole Simpson. Now, it goes from an impossibly small chance, to a much greater chance. Conditional probability, and specifically Bayes’ rule, is used for these kinds of problems.
Bayes’ rule provides guidance for how to update the probability of an event based on new evidence. Named after Thomas Bayes (1701- 1761), more generally, Bayes’ rule, described below, is used to quantify conditional probability. Bayesian probability, where probability is interpreted as reasonably expectation instead of frequency of some event. We discuss Bayesian and Frequentist approaches to hypothesis testing in Chapter 8.2.
Diagnosis from testing.
Let’s turn our attention to medicine. A growing practice in medicine is to claim that decision making in medicine should be based on approaches that give us the best decisions. A search of PubMed texts for “evidence based medicine” found more than 91,944 (13 October 2021, and increase of thirteen thousand since last I looked (10 October, 2019). Evidence based medicine (EBM) is the “conscientious, explicit, judicious and reasonable use of modern, best evidence in making decisions about the care of individual patients” (Masic et al 2008). By evidence, we may mean results from quantitative, systematic reviews, meta-analysis, of research on a topic of medical interest, e.g., Cochrane Reviews.
Note 1: Primary research refers to generating or collecting original data in pursuit of tests of hypotheses. Both systematic reviews and meta-analysis are secondary research or “research on research.” As opposed to a literature review, systematic review make explicit how studies were searched for and included; if enough reasonably similar quantitative data are obtained through this process, the reviewer can combine the data and conduct an analysis to assess whether a treatment is effective (De Vries 2018).
As you know, no diagnostic test is 100% fool-proof. For many reasons, test results come back positive when the person truly does not have the condition — this is a false positive result. Correctly identifying individuals who do not have the condition, 100% – false positive rate, is called the specificity of a test. Think of specificity in this way — provide the test 100 true negative samples (e.g., 100 samples from people who do not have cancer) — how many times out of 100 does the test correctly return a “negative”? If 99 times out of 100, then the specificity rate for this test is 99%. Which is pretty good. But the test results mean more if the condition/disease is common; for rare conditions, even 99% is not good enough. Incorrect assignments are rare, we believe, in part because the tests are generally quite accurate. However, what we don’t consider is that detection and diagnosis from tests also depend on how frequent the incidence of the condition is in the population. Paradoxically, the lower the base rate, the poorer diagnostic value even a sensitive test may have.
To summarize our jargon for interpreting a test or assay, so far we have
- True positive (a), the person has a disease and the test correctly identifies the person as having the disease.
- False positive (b), test result incorrectly identifies disease; the person does not have the disease, but the test classifies the person as having the disease.
- False negative (c), test result incorrectly classifies person does not have disease, but the person actually has the disease.
- True negative (d), the person does not have the disease and the test correctly categorizes the person as not having the disease.
- Sensitivity of test is the proportion of persons who test positive and do have the disease (true positives):

If a test has 75% sensitivity, then out of 100 individuals who do have the disease, then 75 will test positive (TP = true positive). - Specificity of a test refers to the rate that a test correctly classifies a person that does not have the disease (TN = true negatives):

If a test has 90% specificity, then out of 100 individuals who truly do not have the disease, then 90 will test negative (= true negatives).
A worked example. A 50 year old male patient is in the doctor’s office. The doctor is reviewing results from a diagnostic test, e.g., a FOBT — fecal occult blood test — a test used as a screening tool for colorectal cancer (CRC). The doctor knows that the test has a sensitivity of about 75% and specificity of about 90%. Prevalence of CRC in this age group is about 0.2%. Figure 4 shows our probability tree using our natural numbers approach (Fig 4).
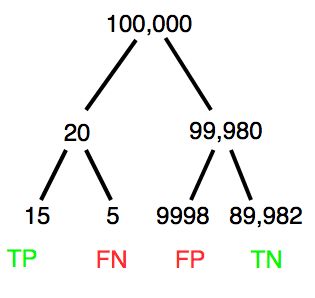
Figure 4. Probability tree for FOBT test; Good test outcomes shown in green: TP stands for true positive and TN stands for true negative. Poor outcomes of a test shown in red: FN stands for false negative and FP stands for false positive.
The associated probabilities for the four possible outcomes of these kinds of tests (e.g., what’s the probability of a person who has tested positive in screening tests actually has the disease?) are shown in Table 1.
Table 1. A 2 X 2 table of possible outcomes of a diagnostic test.
| Person really has the disease | ||
| Test Result | Yes | No |
| Positive | a TP |
b FP |
| Negative | c FN |
d TN |
Bayes’ rule is often given in probabilities,
![\begin{align*} p\left ( D\mid \oplus \right )=\frac{p\left ( D \right )\cdot p\left (\oplus\mid D \right )}{[p\left ( D \right )\cdot p\left (\oplus \right )+p\left ( ND \right )\cdot p\left (\oplus \mid ND \right )]} \end{align*}](https://biostatistics.letgen.org/wp-content/ql-cache/quicklatex.com-fd988801ed9f7a29c963f2df79fcf35c_l3.png "Rendered by QuickLaTeX.com")
Bayes’ rule, where truth is represented by either D (the person really does have the disease”) or ND (the person really does not have the disease”) and ⊕ is symbol for “exclusive or” and reads “not D” in this example.
An easier way to see this is to use frequencies instead. Now, the formula is

Simplified Bayes’ rule, where a is the number of people who test positive and DO HAVE the disease and b is the number of people who test positive and DO NOT have the disease.
Standardized million.
Where did the 100,000 come from? We discussed this in chapter 2: it’s a simple trick to adjust rates to the same population size. We use this to work with natural numbers instead of percent or frequencies. You choose to correct to a standardized population based on the raw incidence rate. A rough rule of thumb:
Table 2. Relationship between standard population size and incidence rate.
| Raw IR rate about | IR | Standard population |
| 1/10 | 10% | 1000 |
| 1/100 | 1% | 10,000 |
| 1/1000 | 0.1% | 100,000 |
| 1/10,000 | 0.01% | 1,000,000 |
| 1/100,000 | 0.001% | 10,000,000 |
| 1/1,000,000 | 0.0001% | 100,000,000 |
The raw incident rate is simply the number of new cases divided by the total population.
Per capita rate.
Yet another standard manipulation is to consider the average incidence per person, or per capita rate. The Latin “per capita” translates to “by head” (Google translate), but in economics, epidemiology, and other fields it is used to reflect rates per person. Tuberculosis is a serious infectious disease of primarily the lungs. Incidence rates of tuberculosis in the United States have trended down since the mid 1900s: 52.6 per 100K in 1953 to 2.7 per 100K in 2019 (CDC). Corresponding per capita values are 5.26 x 10-4 and 2.7 x 10-5, respectively. Divide the rate by 100,000 to get per person rate.
Practice and introduce PPV and Youden’s J.
Let’s break these problems down, and in doing so, introduce some terminology common to the field of “risk analysis” as it pertains to biology and epidemiology. Our first example considers the fecal occult blood test, FOBT, test. Blood in the stool may (or may not) indicate polys or colon cancer. (Park et al 2010).
The table shown above will appear again and again throughout the course, but in different forms.
Table 3. A 2 X 2 table of possible outcomes of FOBT test.
| Person really has the disease | |||
| Yes | No | ||
| Positive | 15 | 9998 | PPV = 15/(15+9998) = 0.15% |
| Negative | 5 | 89,982 | NPV = 89982/(89982+5) = 99.99% |
We want to know how good is the test, particularly if the goal is early detection? This is conveyed by the PPV, positive predictive value of the test. Unfortunately, the prevalence of a condition is also at play: the lower the prevalence, the lower the PPV must be, because most positive tests will be false when population prevalence is low.
Youden (1950) proposed a now widely adopted index that summarizes how effective a test is. Youden’s J is the sum of specificity and sensitivity minus one.

where Se stands for sensitivity of the test and Sp stands for sensitivity of the test.
Youden’s J takes on values between 0, for a terrible test, and 1, for a perfect test. For our FOBT example, Youden’s J was 0.65. This statistic looks like it’s independent of prevalence, but it’s use as a decision criterion (e.g., a cutoff value, above which test is positive, below test is considered negative), assumes that the cost of misclassification (false positives, false negatives) are equal. Prevalence affects number of false positives and false negatives for a given diagnostic test, so any decision criterion based on Youden’s J will also be influenced by prevalence (Smits 2010).
Another worked example. A study on cholesterol-lowering drugs (statins) reported a relative risk reduction of death from cardiac event by 22%. This does not mean that for every 1000 people fitting the population studied, 220 people would be spared from having a heart attack. In the study, the death rate per 1000 people was 32 for the statin versus 41 for the placebo — recall that a placebo is a control treatment offered to overcome potential patient psychological bias (see Chapter 5.4). The absolute risk reduction due to statin is only 41 – 32 or 9 in 1000 or 0.9%. By contrast, relative risk reduction is calculated as the ratio of the absolute risk reduction (9) divided by the proportion of patients who died without treatment (41), which is 22% (LIPID Study Group 1998).
Note that risk reduction is often conveyed as a relative rather than as an absolute number. The distinction is important for understanding arguments based in conditional probability. Thus, the question we want to ask about a test is summarized by absolute risk reduction (ARR) and number needed to treat (NNT), and for problems that include control subjects, relative risk reduction (RRR). We expand on these topics in the next section, 7.4 – Epidemiology: Relative risk and absolute risk, explained.
Evidence Based Medicine.
One culture change in medicine is the explicit intent to make decisions based on evidence (Masic et al 2008). Of course, the joke then is, well, what were doctors doing before, diagnosing without evidence? The comic strip xkcd offers one possible answer (Fig 5).
Figure 5. A summary of “evidence based medical” decisions, perhaps? “Watson Medical Algorithm,” https://xkcd.com/1619/.
As you can imagine, there’s considerable reflection about the EBM movement (see discussions in response to Accad and Francis 2018, e.g., Goh 2018). More practically, our objective is for you to be able to work your way through word problems involving risk analysis. You can expect to be asked to calculate, or at least set up for calculation, any of the statistics listed above (e.g., False negative, false positive, etc.). Practice problems are listed at the end of this section, and additional problems are provided to you (Homework 4). You’ll also want to check your work, and in any real analysis, you’d most likely want to use R.
Software.
R has several epidemiology packages, and with some effort, can save you time. Another option is to run your problems in OpenEpi, a browser-based set of tools. OpenEpi is discussed with examples in the next section, 7.4.
Here, we illustrate some capabilities of the epiR package, expanded more also in the next section, 7.4. We’ll use the example from Table 3.
R code
library(epiR) Table3 <- matrix(c(15, 5, 9998, 89982), nrow = 2, ncol = 2) epi.tests(Table3)
R output
Outcome + Outcome - Total
Test + 15 9998 10013
Test - 5 89982 89987
Total 20 99980 100000
Point estimates and 95% CIs:
--------------------------------------------------------------
Apparent prevalence * 0.10 (0.10, 0.10)
True prevalence * 0.00 (0.00, 0.00)
Sensitivity * 0.75 (0.51, 0.91)
Specificity * 0.90 (0.90, 0.90)
Positive predictive value * 0.00 (0.00, 0.00)
Negative predictive value * 1.00 (1.00, 1.00)
Positive likelihood ratio 7.50 (5.82, 9.67)
Negative likelihood ratio 0.28 (0.13, 0.59)
False T+ proportion for true D- * 0.10 (0.10, 0.10)
False T- proportion for true D+ * 0.25 (0.09, 0.49)
False T+ proportion for T+ * 1.00 (1.00, 1.00)
False T- proportion for T- * 0.00 (0.00, 0.00)
Correctly classified proportion * 0.90 (0.90, 0.90)
--------------------------------------------------------------
* Exact CIs
Oops! I wanted PPV, which by hand calculation was 0.15%, but R reported “0.00?” This is a significant figure reporting issue. The simplest solution is to submit options(digits=6) before the command, then save the output from epi.tests() to an object and use summary(). For example
options(digits=6) myEpi <- epi.tests(Table3) summary(myEpi)
And R returns
statistic est lower upper
1 ap 0.1001300000 0.0982761568 0.102007072
2 tp 0.0002000000 0.0001221693 0.000308867
3 se 0.7500000000 0.5089541283 0.913428531
4 sp 0.9000000000 0.8981238085 0.901852950
5 diag.ac 0.8999700000 0.8980937508 0.901823014
6 diag.or 27.0000000000 9.8110071871 74.304297826
7 nndx 1.5384615385 1.2265702376 2.456532054
8 youden 0.6500000000 0.4070779368 0.815281481
9 pv.pos 0.0014980525 0.0008386834 0.002469608
10 pv.neg 0.9999444364 0.9998703379 0.999981958
11 lr.pos 7.5000000000 5.8193604069 9.666010707
12 lr.neg 0.2777777778 0.1300251423 0.593427490
13 p.rout 0.8998700000 0.8979929278 0.901723843
14 p.rin 0.1001300000 0.0982761568 0.102007072
15 p.tpdn 0.1000000000 0.0981470498 0.101876192
16 p.tndp 0.2500000000 0.0865714691 0.491045872
17 p.dntp 0.9985019475 0.9975303919 0.999161317
18 p.dptn 0.0000555636 0.0000180416 0.000129662
There we go — pv.pos reported as 0.0014980525, which, after turning to a percent and rounding, we have 0.15%. Note also the additional statistics provided — a good rule of thumb — always try to save the output to an object, then view the object, e.g., with summary(). Refer to help pages for additional details of the output (?epi.tests).
What about R Commander menus?
Note 2: Fall 2023 — I have not been able to run the EBM plugin successfully! Simply returns an error message — — on data sets which have in the past performed perfectly. Thus, until further notice, do not use the EBM plugin. Instead, use commands in the epiR package. I’m leaving the text here on the chance the error with the plugin is fixed.
Rcmdr has a plugin that will calculate ARR, RRR and NNT. The plugin is called RcmdrPlugin.EBM (Leucuta et al 2014) and it would be downloaded as for any other package via R.
Download the package from your selected R mirror site, then start R Commander.
install.packages("RcmdrPlugin.EBM")
From within R Commander (Fig 6), select
Tools → Load Rcmdr plug-in(s)…
Figure 6. To install an Rcmdr plugin, first go to Rcmdr → Tools → Load Rcmdr plug-in(s)…
Next, select from the list the plug-in you want to load into memory, in this case, RcmdrPlugin.EBM (Fig 7).
Figure 7. Select the Rcmdr plugin, then click the “OK” button to proceed.
Restart Rcmdr again (Fig 8),
Figure 8. Select “Yes” to restart R Commander and finish installation of the plug-in.
and the menu “EBM” should be visible in the menu bar (Fig 9).
Figure 9. After restart of R Commander the EBM plug-in is now visible in the menu.
Note that you will need to repeat these steps each time you wish to work with a plug-in, unless you modify your .RProfile file. See
Rcmdr → Tools → Save Rcmdr options…
Clicking on the EBM menu item brings up the template for the Evidence Based Medicine module. We’ll mostly work with 2 X 2 tables (e.g., see Table 1) , so select the “Enter two-way table…” option to proceed (Fig 10).
Figure 10. Select “Enter two-way table…”.
And finally, Figure 11 shows the two-way table entry cells along with options. We’ll try a problem by hand then use the EBM plugin to confirm and gain additional insight.
Figure 11. Two-way table Rcmdr EBM plug-in.
For assessing how good a test or assay is, use the Diagnosis option in the EBM plugin. For situations with treated and control groups, use Therapy option. For situations in which you are comparing exposure groups (e.g., smokers vs non-smokers), use the Prognosis option.
Example.
Here’s a simple one (problem from Gigerenzer 2002).
About 0.01% of men in Germany with no known risk factors are currently infected with HIV. If a man from this population actually has the disease, there is a 99.9% chance the tests will be positive. If a man from this population is not infected, there is a 99.9% chance that the test will be negative. What is the chance that a man who tests positive actually has the disease?
Start with the reference, or base population (Figure 12). It’s easy to determine the rate of HIV infection in the population if you use numbers. For 10,000 men in this group, exactly one man is likely to have HIV (0.0001X10,000), whereas 9,999 would not be infected.
For the man who has the disease it’s virtually certain that his results will be positive for the virus (because the sensitivity rate = 99.9%). For the other 9,999 men, one will test positive (the false positive rate = 1 – specificity rate = 0.01%).
Thus, for this population of men, for every two who test positive, one has the disease and one does not, so the probability even given a positive test is only 100*1/2 = 50%. This would also be the test’s Positive Predictive Value.
Note that if the base rate changes, then the final answer changes! For example, if the base rate was 10%
It also helps to draw a tree to help you determine the numbers (Fig 12)
Figure 12. Draw a probability tree to help with the frequencies.
From our probability tree in Figure 12 it is straight-forward to collect the information we need.
- Given this population, how many are expected to have HIV? Two.
- Given the specificity and sensitivity of the assay for HIV, how many persons from this population will test positive? Two.
- For every positive test result, how many men from this population will actually have HIV? One.
Thus, given this population with the known risk associated, the probability that a man testing positive actually has HIV is 50% (=1/(1+1)).
Use the EBM plugin. Select two-way table, then enter the values as shown in Fig 13.
Figure 13. EBM plugin with data entry.
Select the “Diagnosis” option — we are answering the question: How probable is a positive result given information about sensitivity and specificity of a diagnosis test. The results from the EBM functions are given below
Rcmdr> .Table Yes No + 1 1 - 0 9998
Rcmdr> fncEBMCrossTab(.table=.Table, .x='', .y='', .ylab='', .xlab='', Rcmdr+ .percents='none', .chisq='1', .expected='0', .chisqComp='0', .fisher='0', Rcmdr+ .indicators='dg', .decimals=2)
# Notations for calculations Disease + Disease - Test + "a" "b" Test - "c" "d"
# Sensitivity (Se) = 100 (95% CI 2.5 - 100) %. Computed using formula: a / (a + c) # Specificity (Sp) = 99.99 (95% CI 99.94 - 100) %. Computed using formula: d / (b + d) # Diagnostic accuracy (% of all correct results) = 99.99 (95% CI 99.94 - 100) %. Computed using formula: (a + d) / (a + b + c + d) # Youden's index = 1 (95% CI 0.02 - 1). Computed using formula: Se + Sp - 1 # Likelihood ratio of a positive test = 9999 (95% CI 1408.63 - 70976.66). Computed using formula: Se / (Sp - 1) # Likelihood ratio of a negative test = 0 (95% CI 0 - NaN). Computed using formula: (1 - Se) / Sp # Positive predictive value = 50 (95% CI 1.26 - 98.74) %. Computed using formula: a / (a + b) # Negative predictive value = 100 (95% CI 99.96 - 100) %. Computed using formula: d / (c + d) # Number needed to diagnose = 1 (95% CI 1 - 40.91). Computed using formula: 1 / [Se - (1 - Sp)]
Note that the formulas used to calculate Sensitivity, Specificity, etc., follow our Table 1 (compare to “Notations for calculations”). The use of EBM provides calculations of our confidence intervals.
Questions.
- The sensitivity of the fecal occult blood test (FOBT) is reported to be 0.68. What is the False Negative Rate?
- The specificity of the fecal occult blood test (FOBT) is reported to be 0.98. What is the False Positive Rate?
- For men between 50 and 54 years of age, the rate of colon cancer is 61 per 100,000. If the false negative rate of the fecal occult blood test (FOBT) is 10%, how many persons who have colon cancer will test negative?
- For men between 50 and 54 years of age, the rate of colon cancer is 61 per 100,000. If the false positive rate of the fecal occult blood test (FOBT) is 10%, how many persons who do not have colon cancer will test positive?
- A study was conducted to see if mammograms reduced mortality
Mammogram Deaths/1000 women No 4 Yes 3 data from Table 5-1 p. 60 Gigerenzer (2002)
What is the RRR? - A study was conducted to see if mammograms reduced mortality
Mammogram Deaths/1000 women No 4 Yes 3 data from Table 5-1 p. 60 Gigerenzer (2002)
What is the NNT? - Does supplemental Vitamin C decrease risk of stroke in Type II diabetic women? A study conducted on 1923 women, a total of 57 women had a stroke, 14 in the normal Vitamin C level and 32 in the high Vitamin C level. What is the NNT between normal and high supplemental Vitamin C groups?
- Sensitivity of a test is defined as
A. False Positive Rate
B. True Positive Rate
C. False Negative Rate
D. True Negative Rate - Specificity of a test is defined as
A. False Positive Rate
B. True Positive Rate
C. False Negative Rate
D. True Negative Rate - In thinking about the results of a test of a null hypothesis, Type I error rate is equivalent to
A. False Positive Rate
B. True Positive Rate
C. False Negative Rate
D. True Negative Rate - During the Covid-19 pandemic, number of reported cases each day were published. For example, 155 cases were reported for 9 October 2020 by Department of Health. What is the raw incident rate?
Quiz Chapter 7.3
Conditional Probability and Evidence Based Medicine
Chapter 7 contents
- Introduction
- Epidemiology definitions
- Epidemiology basics
- Conditional Probability and Evidence Based Medicine
- Epidemiology: Relative risk and absolute risk, explained
- Odds ratio
- Confidence intervals
- References and suggested readings